UI Feature
Testing
Test Data Generator
Create synthetic vector datasets with configurable distributions for testing, benchmarking, and development.
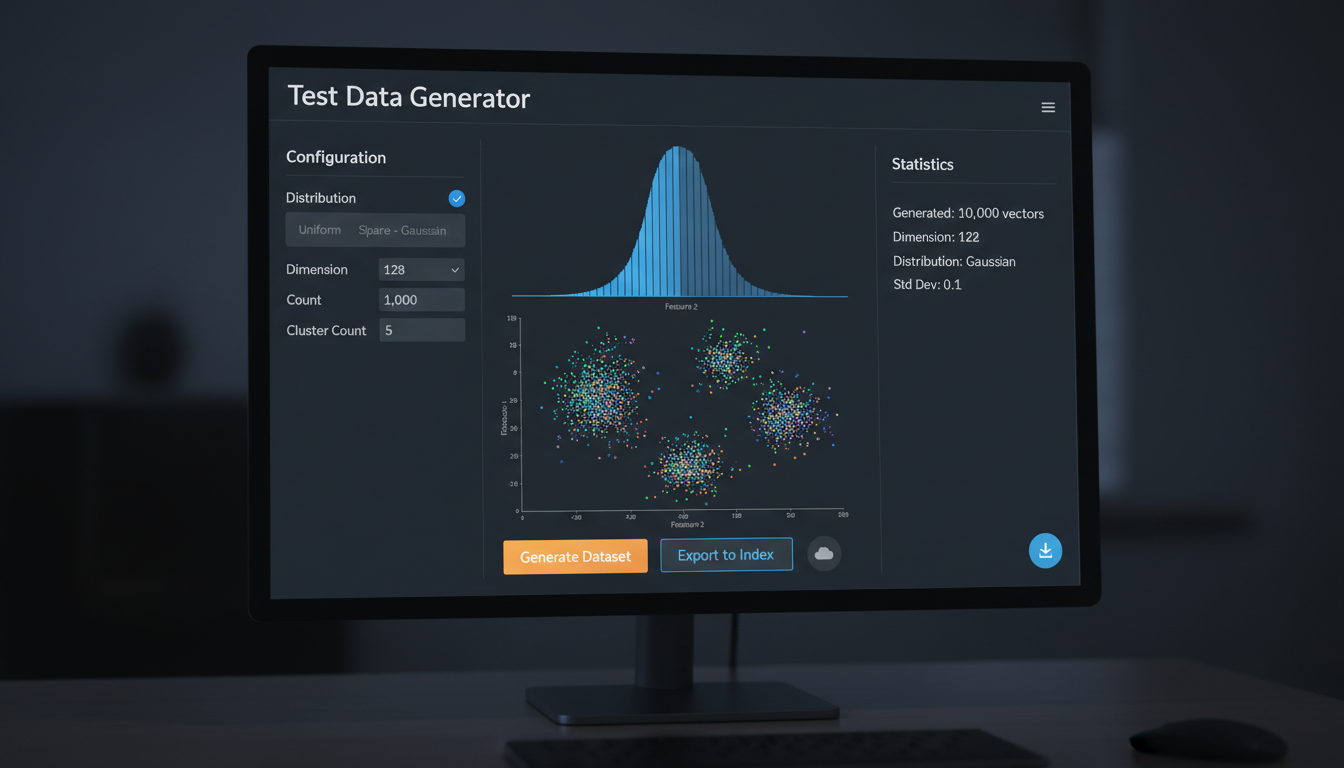
Test data generation interface with distribution previews
Overview
Need test data fast? The Test Data Generator creates synthetic vector datasets with controllable properties. Perfect for load testing, development, or creating reproducible benchmarks without exposing production data.
Distribution Types
Uniform Random
Vectors uniformly distributed in the unit hypercube. Good baseline for testing.
Range: [0, 1] per dimension
Spacing: Random, independent
Spacing: Random, independent
Gaussian
Normal distribution with configurable mean and standard deviation.
Default: μ=0, σ=1
Use: Realistic embedding simulation
Use: Realistic embedding simulation
Clustered
K clusters with Gaussian distribution around each centroid.
Params: k (clusters), σ (spread)
Use: IVF training tests
Use: IVF training tests
Mixed/Custom
Combine distributions or specify custom generation functions.
Format: JSON distribution spec
Use: Edge case testing
Use: Edge case testing
Configuration Options
| Parameter | Description | Default |
|---|---|---|
| count | Number of vectors to generate | 10,000 |
| dimensions | Vector dimensionality | 128 |
| distribution | uniform, gaussian, clustered | gaussian |
| normalize | L2 normalize vectors | true |
| seed | Random seed for reproducibility | random |
| format | Output format (json, fvecs, parquet) | json |
API Example
// Generate test data via API
const response = await fetch('/api/test-data/generate', {
method: 'POST',
body: JSON.stringify({
count: 100000,
dimensions: 256,
distribution: 'clustered',
clusters: 64,
clusterSpread: 0.1,
normalize: true,
seed: 42,
format: 'parquet'
})
});
// Response includes download URL
const { downloadUrl, vectorCount, sizeBytes } = await response.json();
// Or stream directly to index
await fetch('/api/test-data/generate-and-ingest', {
method: 'POST',
body: JSON.stringify({
indexName: 'benchmark-test',
count: 1000000,
distribution: 'gaussian'
})
});Export Formats
- JSON: Array of float arrays, human-readable
- FVECS: Binary format, efficient for FAISS
- Parquet: Columnar, best for large datasets
- NPY: NumPy format for Python pipelines