Architecture
High Availability
Replication and Failover
Primary-replica replication with configurable consistency, automatic failover, and lag monitoring.
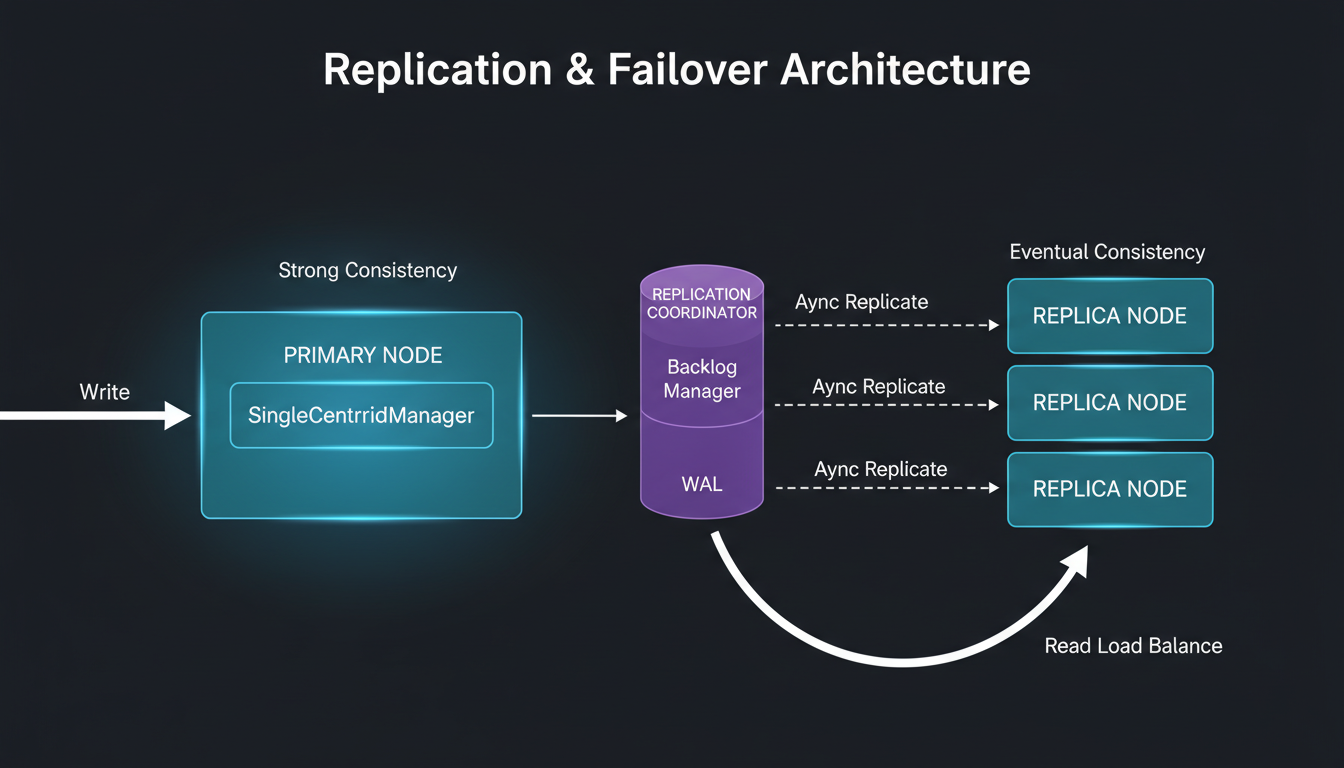
Primary-replica data flow with backlog management
Mirror Groups
A mirror group is a set of nodes maintaining identical copies of data. One node is the primary (handles writes), others are replicas (serve reads).
SYNC
Wait for ALL replicas to acknowledge.
- • Highest durability
- • Highest latency
- • For critical data
SEMI_SYNCDefault
Wait for at least ONE replica.
- • Good durability
- • Moderate latency
- • Recommended
ASYNC
Fire and forget to replicas.
- • Eventual consistency
- • Lowest latency
- • For high throughput
Replication Flow
- 1Write arrives at primary node
- 2Primary writes to local storage + WAL
- 3WAL entry added to BacklogManager queue
- 4BacklogManager streams to replicas
- 5Replicas apply changes, send ACK
- 6Primary confirms write (based on consistency level)
Automatic Failover
// MirrorGroupManager failover configuration
{
"failover": {
"enabled": true,
"detectionInterval": 5000, // Health check every 5s
"failureThreshold": 3, // 3 missed checks = failure
"electionTimeout": 10000, // 10s for election
"priorityList": [ // Preferred failover order
"node-2",
"node-3"
],
"requiresQuorum": true, // Majority must agree
"fencePreviousPrimary": true // Prevent split-brain
}
}Lag Monitoring
Replication Lag Metrics
| Metric | Description | Alert Threshold |
|---|---|---|
| lag_bytes | Backlog size in bytes | > 100MB |
| lag_entries | Number of pending entries | > 10,000 |
| lag_seconds | Time behind primary | > 30s |
Recovery Process
Replica Recovery
- 1. Reconnect: Replica connects to new/existing primary
- 2. Compare: Exchange sequence numbers to find divergence
- 3. Catch-up: Stream missing entries from backlog
- 4. Verify: Checksum validation of recovered state
- 5. Ready: Replica marked healthy, added to read pool