API Feature
Protocol
gRPC vs REST Comparison
MLGraph offers both gRPC and REST APIs. Choose the right one based on your use case, client capabilities, and performance requirements.
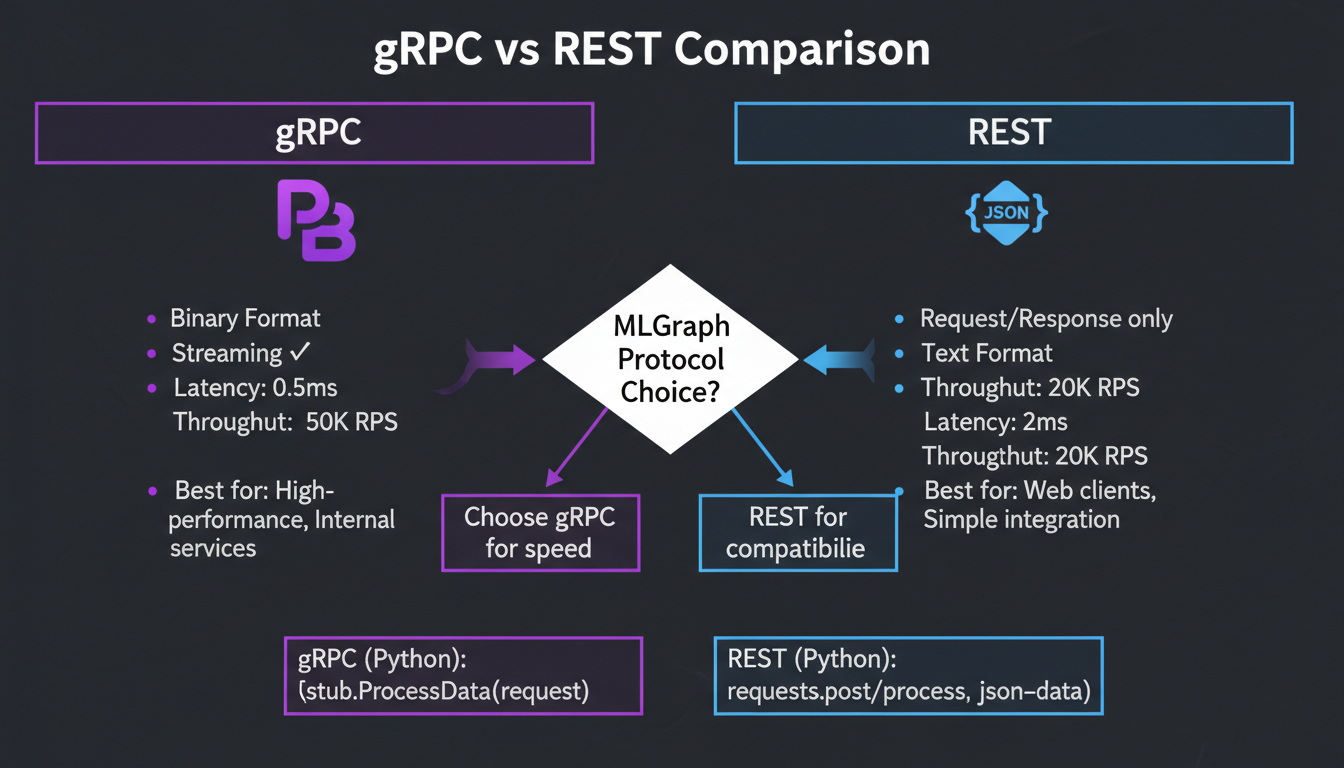
Protocol comparison: when to use each
Quick Comparison
| Feature | gRPC | REST |
|---|---|---|
| Transport | HTTP/2 | HTTP/1.1 or HTTP/2 |
| Encoding | Protobuf (binary) | JSON (text) |
| Latency (p50) | 0.8ms | 2.1ms |
| Throughput | 15,000 QPS | 8,000 QPS |
| Streaming | Bidirectional | SSE only |
| Browser Support | grpc-web | Native |
| Debugging | Requires tools | curl, browser |
When to Use gRPC
Use gRPC When
- • Microservice-to-microservice calls
- • High-throughput batch operations
- • Streaming search results
- • Low-latency is critical
- • Type-safe client generation
Avoid gRPC When
- • Browser-based applications
- • Quick prototyping/debugging
- • Third-party integrations
- • Serverless environments
- • Limited language support
gRPC Example
// Proto definition (mlgraph.proto)
service VectorService {
rpc Search(SearchRequest) returns (SearchResponse);
rpc SearchStream(SearchRequest) returns (stream SearchResult);
rpc BatchAdd(stream AddRequest) returns (BatchAddResponse);
}
message SearchRequest {
string index = 1;
repeated float vector = 2;
int32 k = 3;
int32 nprobe = 4;
}
// Client usage (Python)
import grpc
from mlgraph_pb2_grpc import VectorServiceStub
from mlgraph_pb2 import SearchRequest
channel = grpc.insecure_channel('mlgraph:50051')
stub = VectorServiceStub(channel)
response = stub.Search(SearchRequest(
index="my-vectors",
vector=query_vector,
k=10,
nprobe=16
))
for result in response.results:
print(f"ID: {result.id}, Distance: {result.distance}")REST Example
// REST API
POST /api/v1/indexes/my-vectors/search
Content-Type: application/json
Authorization: Bearer mlg_xxx
{
"vector": [0.1, 0.2, 0.3, ...],
"k": 10,
"nprobe": 16,
"includeMetadata": true
}
// Response
{
"results": [
{ "id": "doc-123", "distance": 0.12, "metadata": {...} },
{ "id": "doc-456", "distance": 0.18, "metadata": {...} }
],
"metrics": {
"latencyMs": 2.3,
"clustersSearched": 16
}
}
// cURL
curl -X POST https://api.mlgraph.io/v1/indexes/my-vectors/search \
-H "Authorization: Bearer mlg_xxx" \
-H "Content-Type: application/json" \
-d '{"vector": [...], "k": 10}'Recommendation
Our Recommendation
- Internal services: Use gRPC for 2x lower latency and streaming
- Web clients: Use REST for browser compatibility
- Both: They share the same backend—use whichever fits your client