Cluster Architecture
Scale from 1 to 50+ nodes with automatic replication, sharding, and failover. Built for production-grade vector search with 99.9% availability guarantees.
Architecture Overview
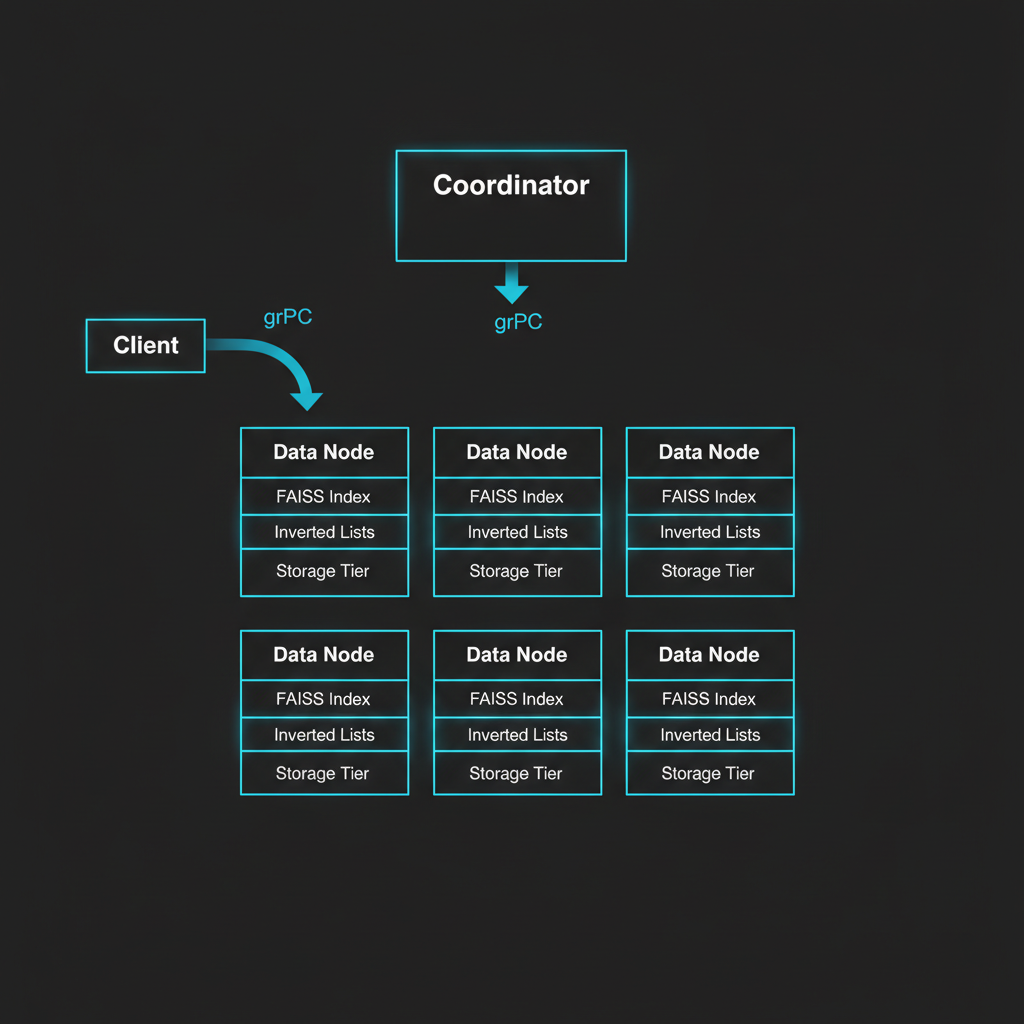
MLGraph's cluster architecture distributes vector storage across multiple nodes, coordinated by a lightweight coordinator service. Each data node hosts FAISS indexes for assigned centroids, with automatic replication for fault tolerance.
Coordinator Node
Maintains cluster state, handles leader election, manages replica placement and failover
Data Nodes
Store vector data in FAISS indexes with tiered storage (IDMap, IVF, OnDisk)
Replication & Sharding

Why Sharding Matters for Vector Search
Unlike traditional databases where you can just throw more RAM at the problem, vector search has a dirty secret: FAISS indexes don't scale linearly with data size. The inverted file (IVF) algorithm used for approximate nearest neighbor search gets slower as indexes grow beyond a few hundred million vectors.
Sharding distributes vectors across multiple smaller indexes, each operating at peak efficiency. A 1 billion vector dataset split across 10 nodes (100M vectors each) searches faster than a single 1B vector index—even accounting for network overhead.
Basic Replication (n-way)
Each centroid replicated across n servers
Sharding + Replication
Data partitioned across shards, each shard replicated
Cross-Region Replication
Asynchronous replication to secondary regions
Shard Placement Algorithm
The DistributedIndexManager uses a consistent hashing algorithm to assign centroids to nodes. When a new node joins the cluster:
- Coordinator calculates centroid assignments based on cluster topology
- Affected centroids are migrated to new node in background
- Replicas are created on other nodes for fault tolerance
- Health checker validates data consistency across replicas
Reads continue to be served from old locations during migration. Writes are buffered and replayed on new nodes. Zero downtime, zero data loss.
Failover & Recovery
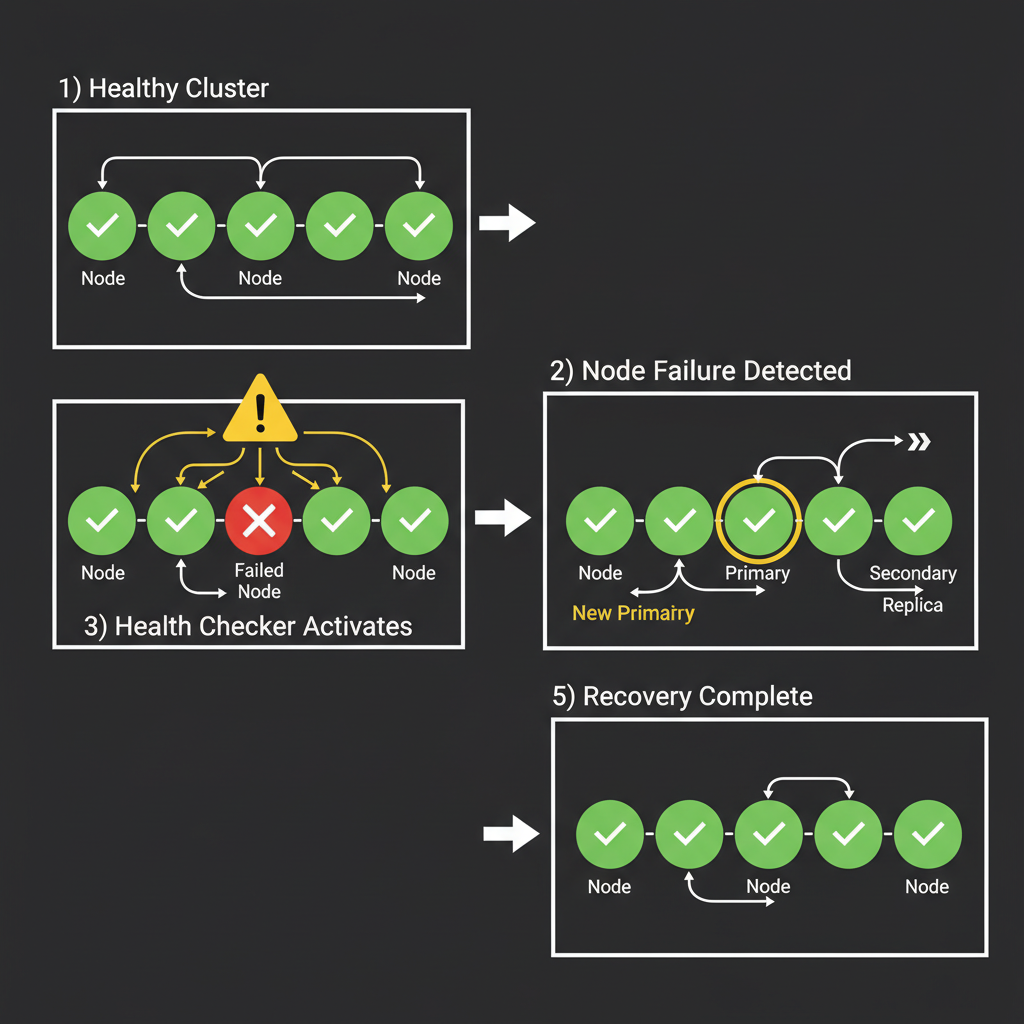
Health Checking
The HealthChecker service periodically pings each data node with lightweight gRPC health checks:
- gRPC health check every 5 seconds (configurable)
- 3 consecutive failures trigger failover
- Circuit breaker prevents cascading failures
- Automatic recovery when node returns
Automatic Failover
When a primary replica fails, the coordinator promotes a healthy replica:
- Detect failure (health check timeout)
- Select best replica (lowest latency)
- Update cluster state (atomic)
- Notify clients (via gRPC metadata)
Disaster Recovery
Beyond automatic failover, MLGraph supports point-in-time recovery from snapshots:
Snapshotting
- Periodic FAISS index snapshots
- Metadata backup to key-value store
- Store in object storage (S3, GCS)
Restoration
- Full cluster restore from snapshot
- Individual node recovery
- Automated runbooks for common scenarios
Cluster Scaling

Scaling Characteristics
MLGraph demonstrates excellent scaling efficiency up to 10 nodes, with near-linear throughput improvements and sub-linear overhead. The sweet spot for most use cases is 3-5 nodes, balancing performance, cost, and operational complexity.
1 Node
Development & small datasets
3 Nodes
Production starter (recommended)
5 Nodes
High availability
10+ Nodes
Large-scale deployments