MLGraph System Architecture
MLGraph is a distributed vector database that combines the power of FAISS-based indexing with a horizontally scalable, fault-tolerant architecture. Inspired by turbopuffer's design philosophy, MLGraph implements distributed vector search in C++ with gRPC communication, S3-backed persistence, TBB parallelism, and enterprise-grade security.
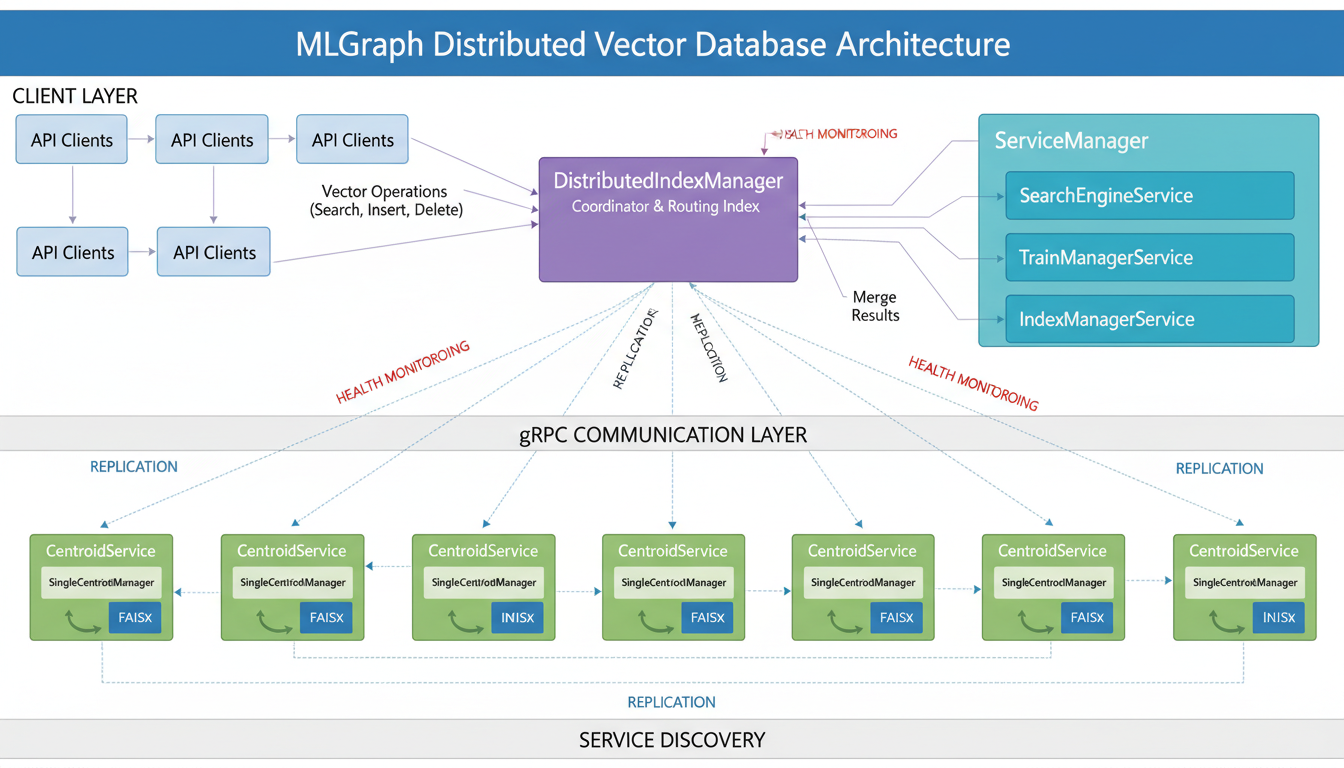
MLGraph high-level architecture: distributed components, gRPC communication, and service orchestration
At its core, MLGraph solves a fundamental problem: how do you search billions of high-dimensional vectors when they don't fit on a single machine? The answer lies in breaking the index into centroids (think of them as "vector neighborhoods") and distributing those centroids across multiple servers. When a query comes in, we only need to check the most relevant centroids, not the entire dataset.
Here's the mental model: imagine organizing a massive library. Instead of scanning every book, you first check which sections (centroids) are most relevant to your topic, then search only within those sections. MLGraph does this, but for vectors.
Three-Tier Storage System
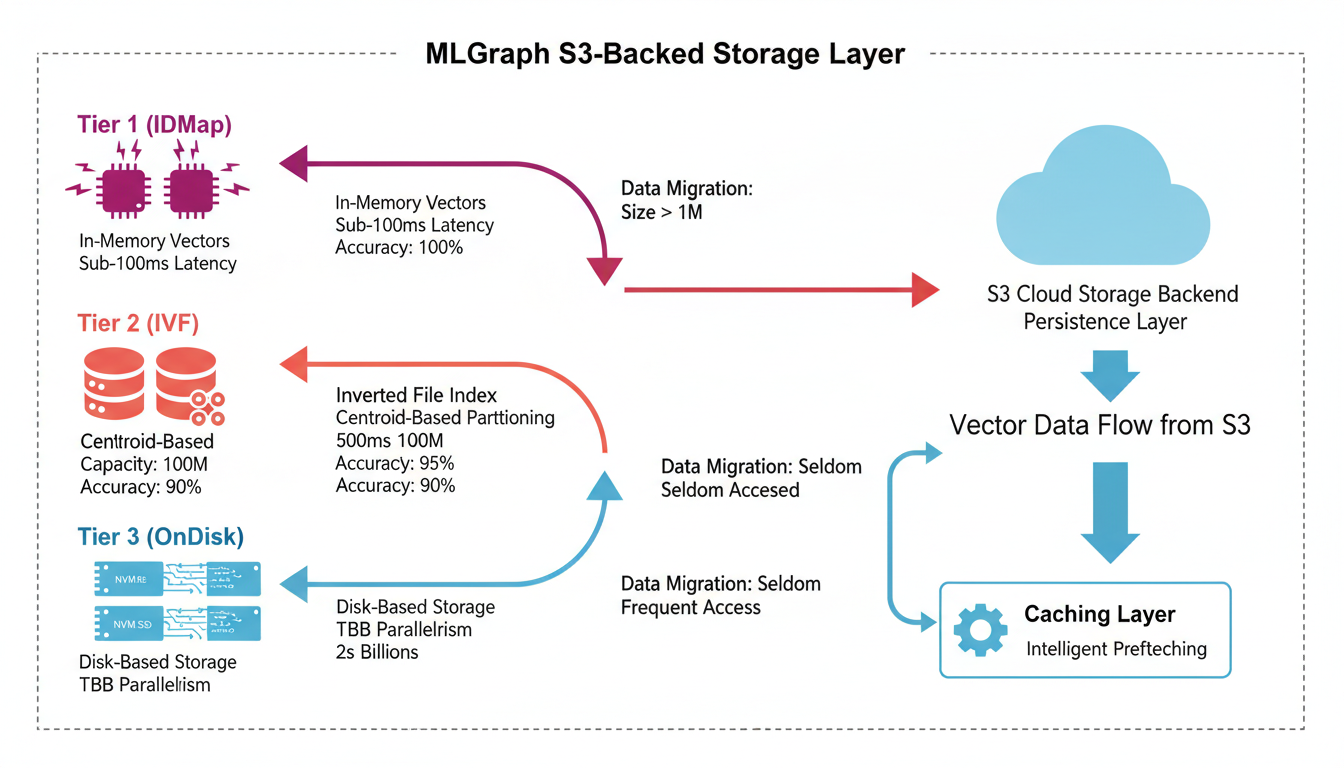
Three-tier storage architecture with S3-backed persistence and intelligent caching
MLGraph uses a three-tier storage strategy, each optimized for different dataset sizes and latency requirements:
Tier 1: IDMap (In-Memory)
For datasets under 1GB that need sub-100ms latency
IndexIDMap stores all vectors in RAM with exact brute-force search. No approximation, no compression—just raw speed. Perfect for high-value, frequently-queried datasets like user embeddings or product catalogs.
Tier 2: IVF (Inverted File)
For datasets 10GB+ with configurable accuracy/speed tradeoff
IndexIVFFlat partitions vectors into clusters (centroids). Search uses nprobe to check only the N closest clusters. This is the sweet spot for most workloads—fast enough for production, accurate enough for high recall.
Tier 3: OnDisk Storage
For billion-scale datasets that exceed RAM capacity
OnDiskInvertedLists (with TBB parallelism) stores inverted lists on disk with intelligent caching. Search streams data from NVMe SSDs in parallel. Handles datasets that would bankrupt you if you tried to keep them in RAM.
Core Components
DistributedIndexManager
The brain of the operation
This component coordinates everything: creates indices, routes vectors to the right servers, orchestrates searches. It manages the routing index—a top-level FAISS index that quickly determines which centroids are relevant for a query.
Key insight: The DistributedIndexManager doesn't actually store vectors—it's pure coordination. The real data lives in CentroidService instances running on each server.
CentroidService
The workhorses
Each server runs a CentroidService that stores vectors using FAISS IVF indices with on-disk inverted lists, handles local operations (add, search, delete within assigned centroids), and provides size tracking.
The clever bit: CentroidService uses SingleCentroidManager instances—one per centroid. This makes it trivial to move centroids between servers (just serialize the FAISS index and ship it).
ServiceManager
The orchestrator
Manages core services (SearchEngineService, TrainManagerService, IndexManagerService), handles lifecycle (startup, health checks, graceful shutdown), supports configuration hot-reload, and tracks performance metrics for all running services.
The Search Flow
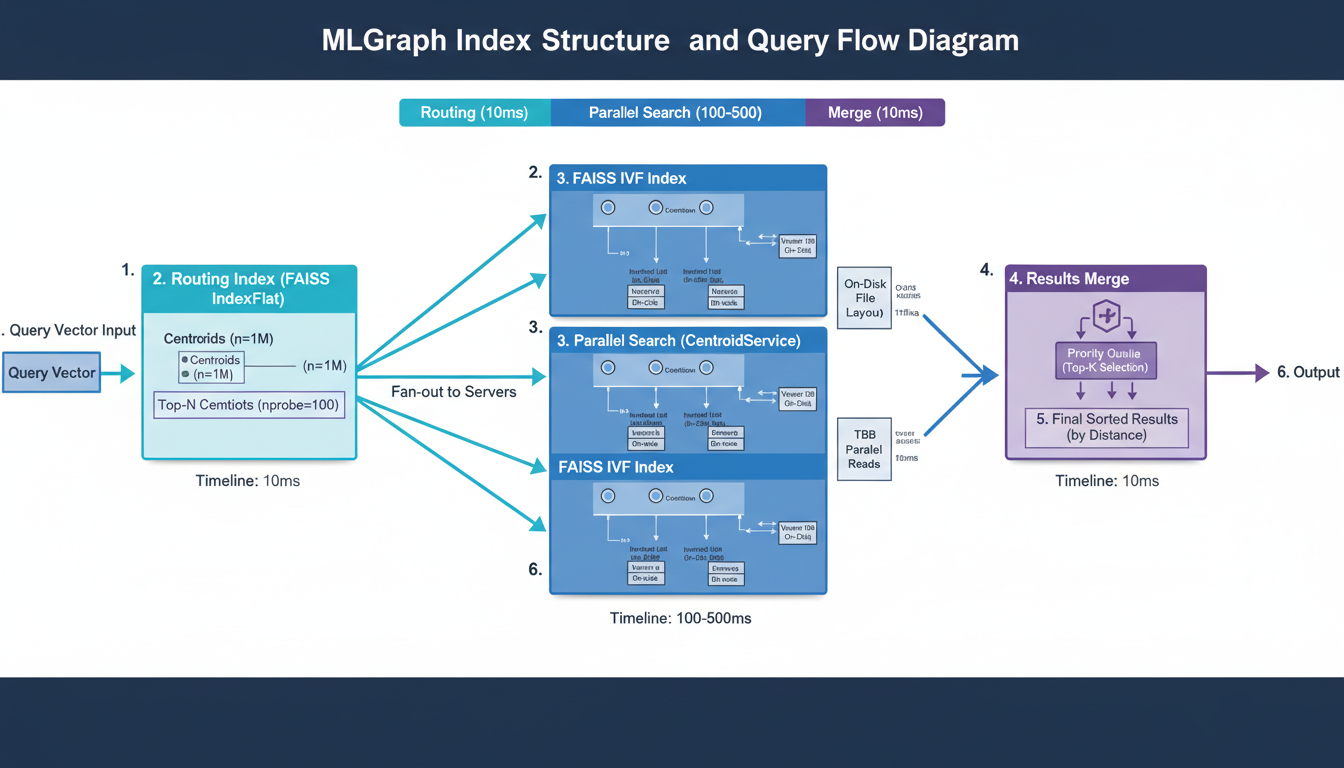
Query flow pipeline: routing index, parallel fan-out, IVF search, and results merge
Let's trace what happens when you search for the top 10 nearest neighbors:
Why this is fast: We only search ~0.5% of the data (5 out of 1000 centroids), and we do it in parallel across multiple machines. This is the IVF (Inverted File) algorithm at scale.
Distributed Training Workflow
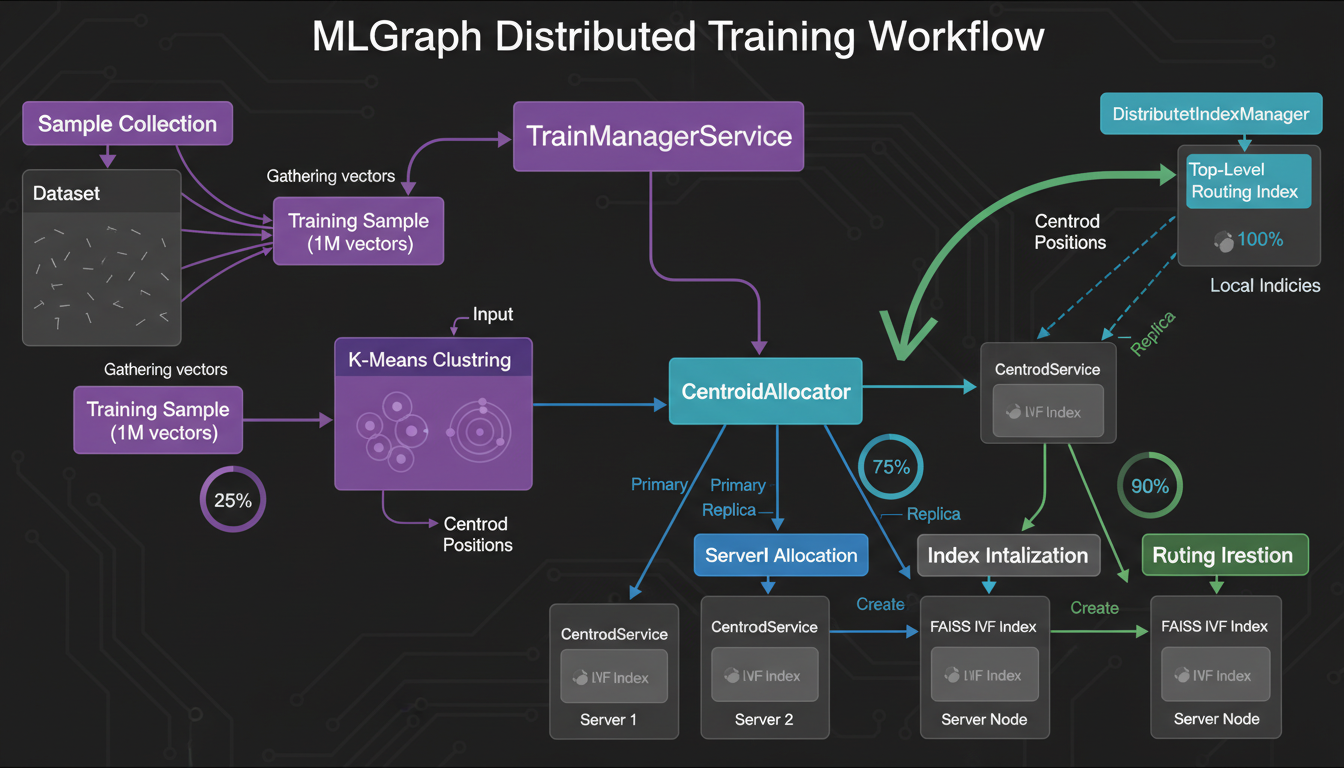
Multi-stage training: sample, cluster, allocate, initialize, build routing index
Here's a chicken-and-egg situation: to route vectors to centroids, we need trained centroids. But to train centroids, we need vectors. How do we start?
Multi-Stage Training
Orchestrated by TrainManagerService
This happens once per index. After that, centroids are fixed (or updated via retraining).
Failure Handling and Replication

Health monitoring, replica promotion, and quorum writes for consistency
Distributed systems fail. Disks die. Networks partition. Power goes out. MLGraph handles this gracefully:
Server Failures
Partial Failures
Split Brain Prevention
Scalability Limits
How far can this scale?
S3-Backed Persistence
While MLGraph stores vectors locally for fast access, all data is backed by S3-compatible object storage for durability and cost efficiency. This hybrid approach gives you the speed of local NVMe SSDs with the economics and reliability of cloud object storage.
Hybrid Storage Strategy
The system tracks access patterns and automatically promotes hot data to local storage while evicting cold data back to S3. This means you pay for SSD capacity only for what you're actively searching, while the bulk of your data lives cheaply in object storage.
Enterprise Security with TLS
MLGraph supports optional TLS/SSL encryption for all gRPC communications. In production, you probably want this enabled—vector embeddings often represent sensitive data like user preferences or proprietary documents.
Server-Side TLS
All gRPC connections encrypted with TLS 1.2+. Uses modern cipher suites (AES-256-GCM, ChaCha20-Poly1305). Certificate verification prevents man-in-the-middle attacks.
--tls-cert server.crt \
--tls-key server.key
Mutual TLS (mTLS)
For zero-trust environments, enable client certificate authentication. Both client and server verify each other's identity before any data is exchanged.
--tls-ca client-ca.crt \
--require-client-cert
Certificate Management
MLGraph provides helpers for certificate generation and validation. In production, use certificates from a trusted CA (Let's Encrypt, AWS ACM, etc.) and implement rotation before expiry.
Parquet Training Data Support
When you're training indices on billions of vectors, you need an efficient file format. MLGraph supports Apache Parquet for training data—compressed, columnar, and blazing fast to read.
Why Parquet for Training Data?
Supported Formats
The system auto-detects format by file extension (.parquet) and validates dimensions on load. If a vector doesn't match the expected dimension, you get an immediate error instead of silent corruption.
Why C++ and gRPC?
You might wonder: why not use a Python service with Flask/FastAPI? Two reasons: