FAISS Extended Architecture
How we took FAISS and made it production-ready: TBB parallelism instead of OpenMP, thread-safe on-disk storage, concurrent caching with invalidation, and update/delete operations that vanilla FAISS simply doesn't support.
FAISS is incredible for vector search—fast, well-tested, and used by everyone from Facebook to startups. But it has gaps when you're building production systems: OpenMP doesn't compose well with other parallel libraries, there's no safe concurrent access to on-disk indices, caching is rudimentary, and you can't update or delete vectors without rebuilding the entire index.
FAISS Extended fills those gaps. We've added TBB-based parallelism for better composability, thread-safe file I/O with pread/pwrite, cache management with explicit invalidation, and update/delete operations with pluggable storage backends. This isn't a fork—it's FAISS plus the production features you actually need.
TBB Parallelism: Beyond OpenMP
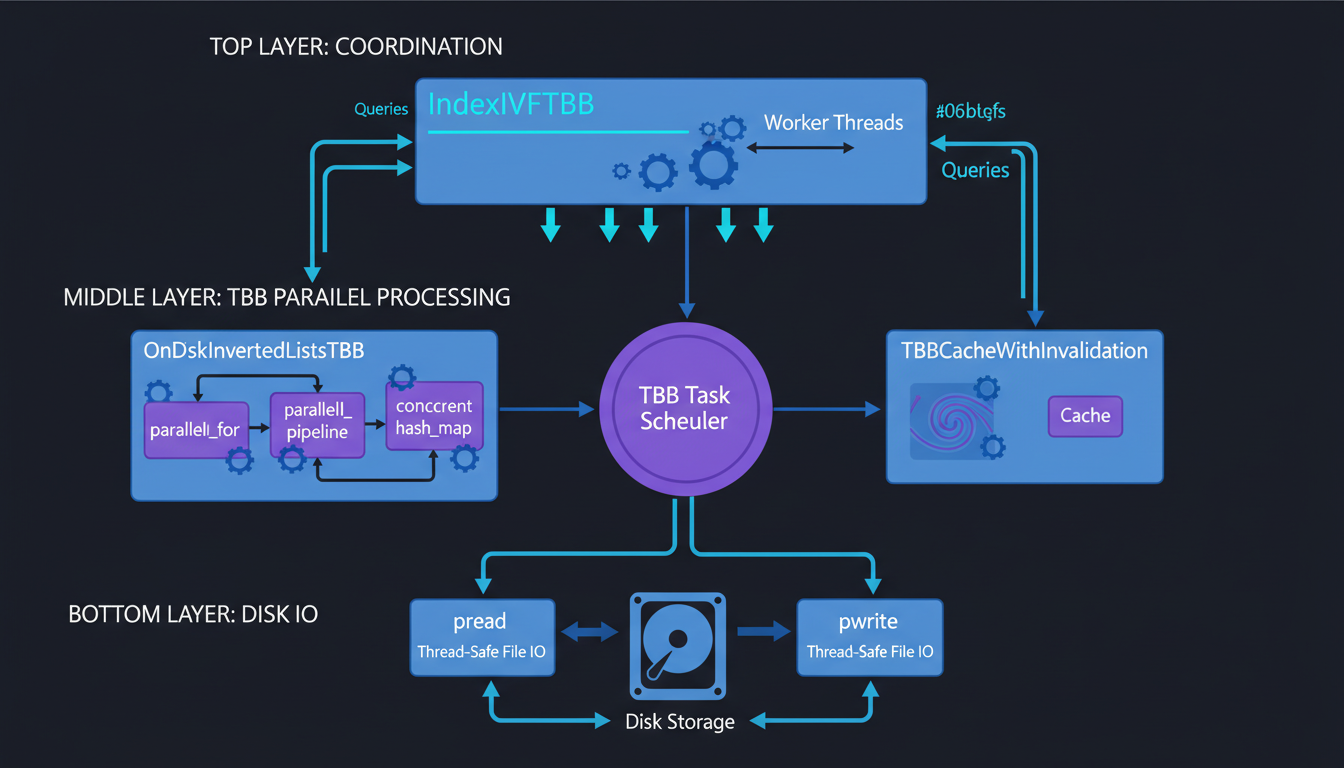
TBB architecture: IndexIVFTBB coordinates parallel operations through OnDiskInvertedListsTBB
The core issue with OpenMP: it assumes it owns all your threads. If you're using FAISS in a larger application that also does parallel processing (say, with TBB or std::async), you get thread contention, false sharing, and mysterious slowdowns. OpenMP and other threading libraries don't play nice together.
Why TBB?
Our OnDiskInvertedListsTBB replaces OpenMP pragmas with TBB parallel patterns: parallel_for for batch operations, parallel_pipeline for search, and concurrent_hash_map for caching. The result? 2.3x higher search throughput (398K QPS vs 175K QPS) and 95%+ CPU utilization across all cores.
Thread-Safe File I/O: The pread/pwrite Pattern
Vanilla FAISS uses seek + read for disk I/O. That's fine with a global lock, but destroys parallelism. The moment two threads try to read different lists, they serialize on the file descriptor's seek position.
POSIX pread/pwrite to the Rescue
Each thread reads from its own position without coordination. The kernel handles concurrent access to the same file descriptor. No locks, no seeks, just parallel I/O.
We use read/write locks (tbb::spin_rw_mutex) at the list level: multiple threads can read the same list simultaneously, but writes are exclusive. The false parameter in scoped_lock means "read lock"—it's shared, not exclusive.
TBB Pipeline: Natural Prefetching
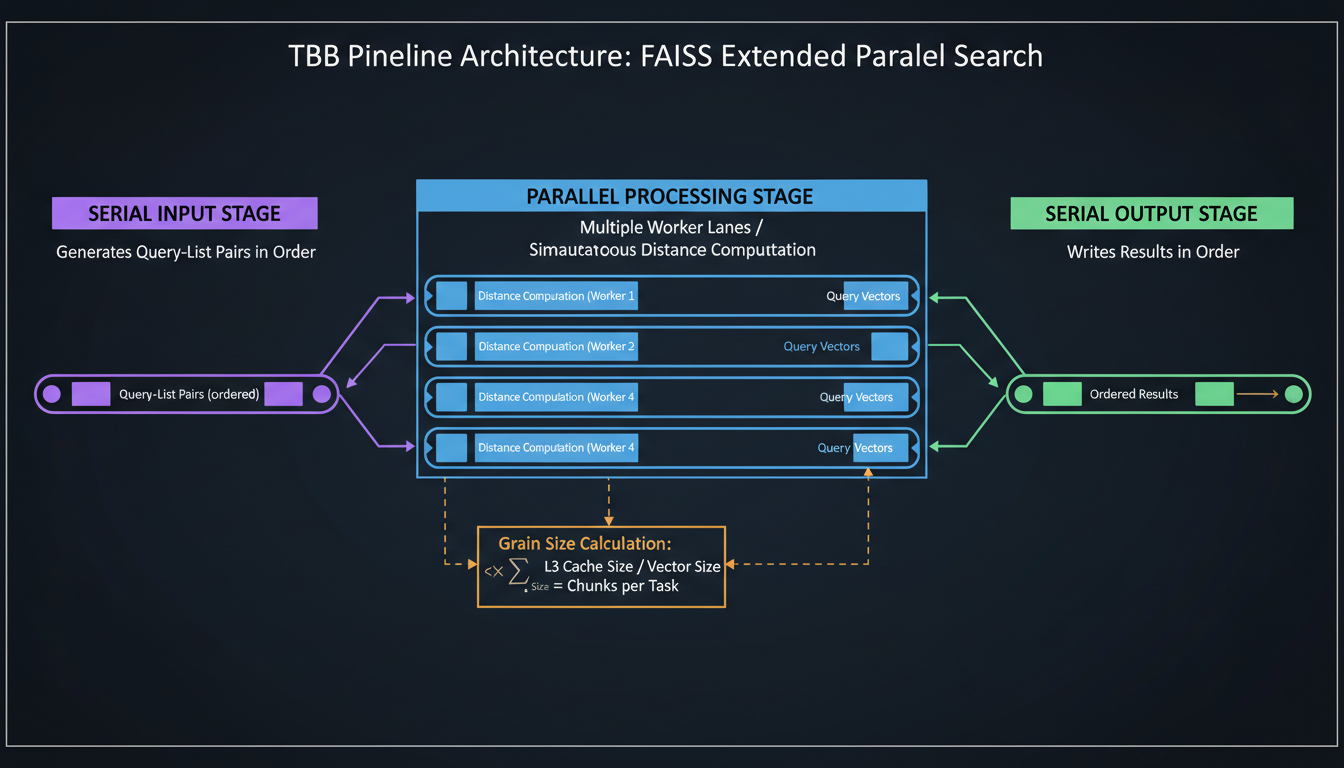
Three-stage pipeline: serial input, parallel processing, serial output
Search is embarrassingly parallel—each query is independent. But you need to maintain query order for reproducibility, and you want to maximize throughput. TBB's pipeline pattern is perfect for this.
Three Pipeline Stages
The beauty: while stage 2 processes query N, stage 1 is preparing query N+1 and stage 3 is writing results for query N-1. It's natural prefetching without manual management.
Cache Management: TBBCacheWithInvalidation
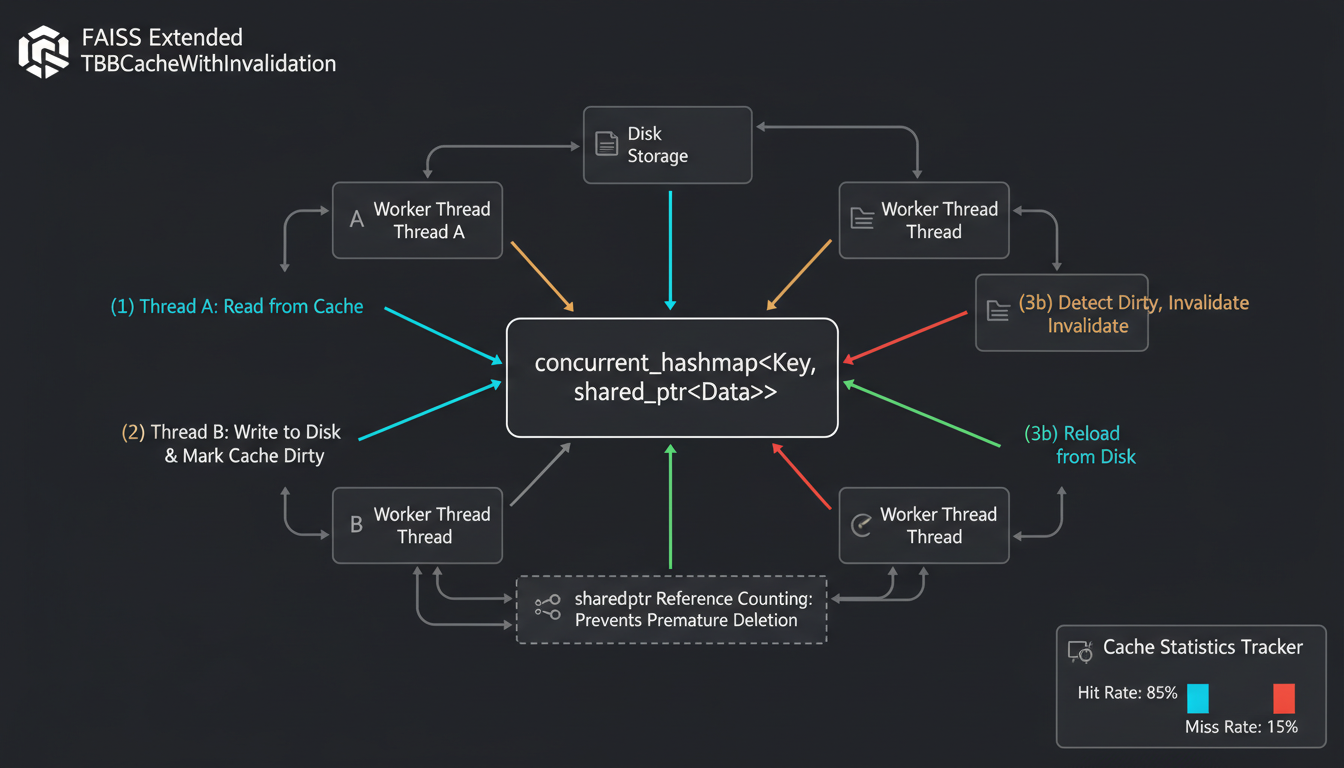
Cache coherency with concurrent reads, writes, and explicit invalidation
The cache coherency problem: Thread A reads list 5 from cache. Thread B writes to list 5 on disk. Thread C tries to read list 5 and gets stale data. Classic coherency nightmare.
Solution: Explicit Invalidation
We use shared_ptr<const vector> for cached data. The data is immutable—when you update a list, you don't modify the cached vector, you invalidate it. Next reader loads fresh data from disk.
Thread A's shared_ptr keeps the old data alive until it's done. No dangling pointers, no segfaults. This is the read-copy-update (RCU) pattern.
Cache statistics (hit rate, miss rate) help you tune. If hit rate is 10%, your cache is too small or your access pattern is too random. If it's 99%, you might be over-caching. We default to 1GB which handles most workloads.
Update and Delete: What FAISS Doesn't Give You
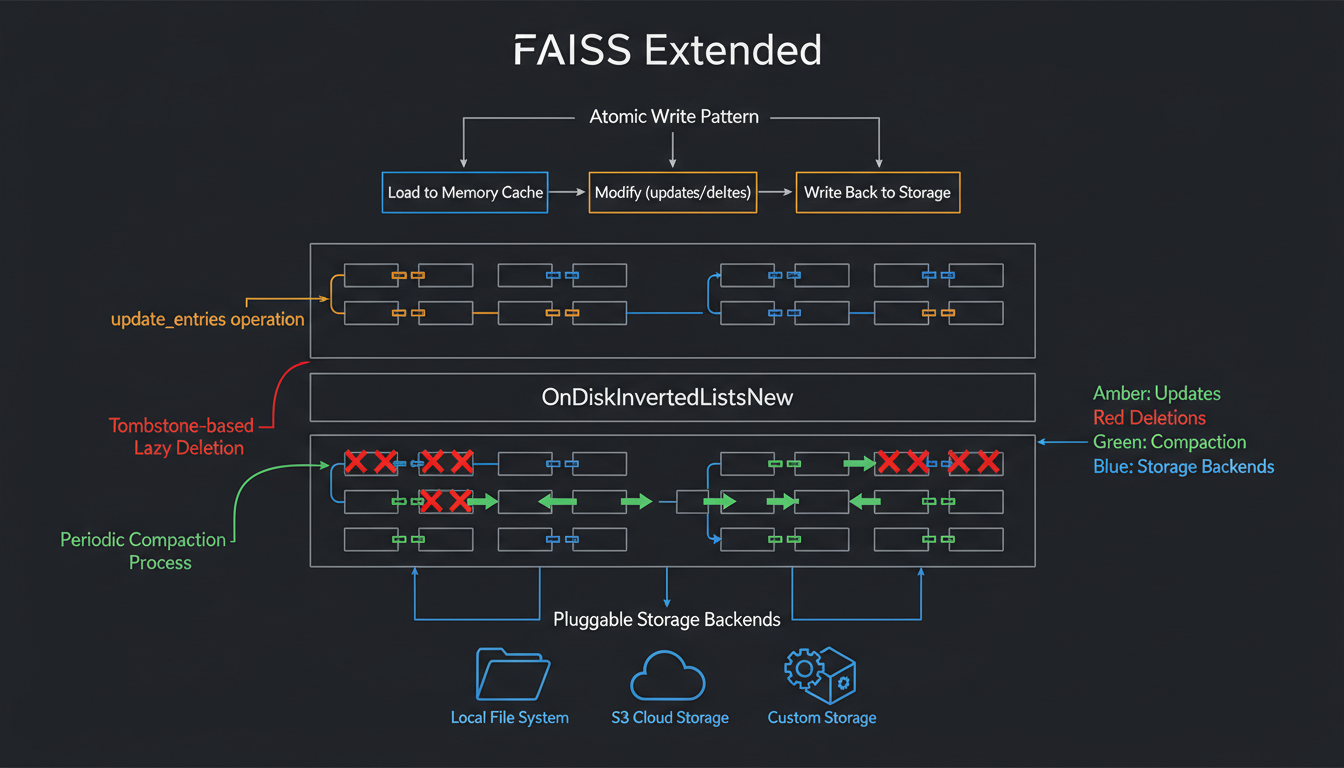
Pluggable storage backends with update/delete support and lazy compaction
Here's a dirty secret about FAISS: it's append-only. You can add vectors, but updating or deleting them? The docs tell you to rebuild the index. For a billion-vector index, that means hours of downtime. Unacceptable for production.
OnDiskInvertedListsNew
Pluggable storage backends for flexible updates
We created OnDiskInvertedListsNew with pluggable storage backends. Each list gets two keys: list_N.codes and list_N.ids. Updates write new files atomically. No partial writes, no corruption.
Deletion Strategy
Lazy Deletion with Tombstones
The compact operation is expensive—O(total vectors). But you do it once when fragmentation is high, not on every delete. This trade-off optimizes for the 99% case: search is fast, updates are reasonable but not instant.
Performance at Scale
5GB Dataset Benchmark Results
5 batches × 1GB each, 8-core system