The Latent Bridge: How Our 8 SLMs Talk Without Words
Here's a dirty secret about multi-agent AI systems: when your models "talk" to each other, they're doing something monumentally wasteful. Model A has this rich, high-dimensional representation of what it understood—4096 dimensions of pure semantic geometry—and then it flattens it into tokens. Plain text. Model B reads those tokens and has to rebuild the entire semantic structure from scratch. It's like two mathematicians communicating by describing equations in interpretive dance, then transcribing the dance back to math. Why not just... share the math?

The latent bridge: direct semantic transfer between model representation spaces
The Token Bottleneck: Why Text-Based Model Communication Sucks
We have 8 specialist SLMs in our ensemble: C++, CMake, Debug, Shell, Orchestrator, Design, Review, and Algorithm. When you ask "why is this template failing to compile?", the Orchestrator routes to Debug SLM, which might need context from C++ SLM, which might consult Algorithm SLM for complexity analysis. That's three models that need to share understanding.
Traditional approach? Each model generates text, the next model reads it. Every handoff forces a model to:
Compress 4096-dimensional semantic geometry into a linear sequence of discrete tokens. Information loss is inevitable—you can't losslessly compress a hypersphere into a string.
The receiving model runs its full embedding pipeline on the token sequence. That's O(n²) attention over text that was already understood by another model moments ago.
Subtle semantic relationships—the kind that matter for understanding template metaprogramming or memory ownership—get blurred in translation. The receiving model sees words, not meaning.
The computational waste is staggering. In a complex query that touches 4 models, you're paying the full inference cost 4 times, plus tokenization/detokenization overhead at each boundary. And that's before we count the semantic information that simply gets lost in translation.
The Insight: Semantic Spaces Are More Similar Than You'd Think
Recent research from UC Santa Cruz (Yang & Eshraghian, 2025) demonstrated something remarkable: you can learn bidirectional vector translations between completely different LLMs. They trained a dual-encoder translator between Llama-2-7B and Mistral-7B-Instruct—models with different architectures, different training data, different purposes—and achieved 0.538 average cosine alignment across diverse domains. That's not perfect, but it's meaningful semantic transfer.
The key insight: inject translated vectors at 30% blending strength into the target model's final transformer layers, and you get semantic steering without destabilizing the model's natural processing. The target model incorporates the semantic "hint" from the source while maintaining its own computational integrity.
The Research Foundation
"Direct Semantic Communication Between Large Language Models via Vector Translation" (arXiv:2511.03945) proved that:
- Learned vector translations can bridge different model architectures
- 30% blending preserves computational stability while enabling transfer
- General-purpose models yield more transferable representations (2.01:1 asymmetry)
- Precision tasks (code, math) remain stable under vector injection
This was exactly what we needed. Our 8 SLMs already have space converters for tokenizer bridging—but those operate at the token level. What if we could go deeper? What if our models could share their actual semantic understanding directly?
The Latent Bridge: How We Wired 8 Models Together
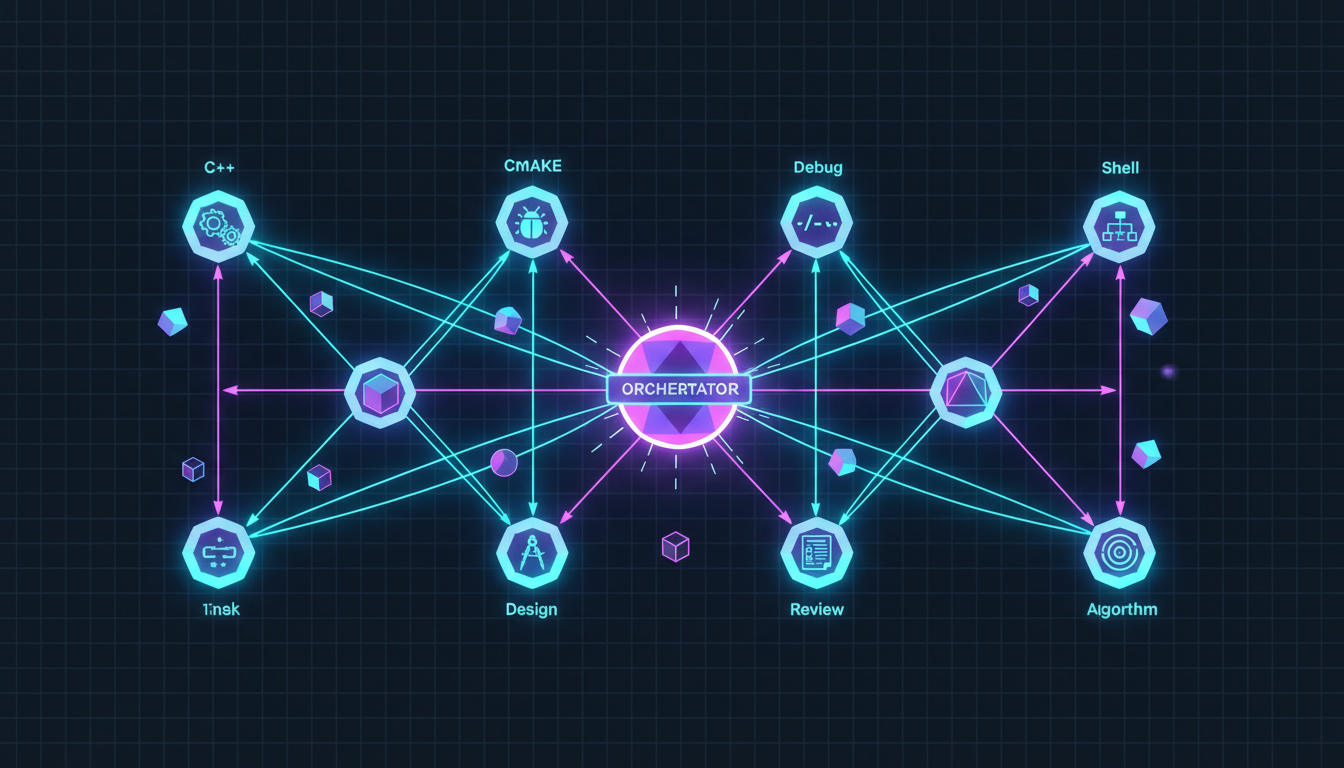
The 8-model mesh: every specialist can share semantic vectors with every other
Our implementation extends the dual-encoder approach to handle 8 models with different hidden dimensions and specialized tokenizers. The challenge: with 8 models, you potentially need 56 bidirectional translators (8 × 7). That's a lot of parameters to train and maintain.
Our Solution: Hub-and-Spoke with Shared Semantic Space
Instead of N² translators, we project all 8 models into a shared 512-dimensional semantic space:
Result: 16 small networks instead of 56. Any model can communicate with any other through the shared space.
The shared semantic space isn't just dimensionality reduction—it's a learned lingua franca where concepts from different domains align. When Debug SLM encodes "null pointer dereference", it lands near where C++ SLM encodes "undefined behavior from dereferencing nullptr". The space learns that these are semantically equivalent across domains.
Dual-Encoder Architecture: The Technical Details

The dual-encoder translator: compress, align, expand, inject
Translation Pipeline (Per Model Pair)
Extract the final hidden states from the source model (e.g., 3072D from C++ SLM). We use the last 3 token positions where semantic information consolidates for generation decisions.
Project through the source encoder to 512D shared space. Multi-head attention (8 heads) learns cross-domain alignment during training.
Decode from shared space to target model's dimensionality (e.g., 2048D for Debug SLM). The decoder learns to produce vectors that "make sense" in the target's representation space.
Blend translated vectors into target model's final 3 layers at 30% strength:h'_i = 0.7 × h_i + 0.3 × v_translatedThis preserves the target model's natural processing while introducing semantic guidance.
The training loss combines four components: direct translation loss (MSE between translated and target vectors), cycle consistency loss (translate A→B→A should reconstruct A), contrastive loss (similar concepts should cluster in shared space), and distribution preservation loss (translated vectors should have similar statistics to native vectors).
How It Works: A Real Query Flow
Let's trace a complex query through the system: "Why does this SFINAE expression fail, and how can I rewrite it with C++20 concepts?"
Orchestrator SLM analyzes: this needs Debug SLM (understand failure) + C++ SLM (SFINAE expertise) + Design SLM (modernization strategy).
Debug SLM processes the error, produces analysis, AND exports its semantic representation (2048D vector encoding "template substitution failure in enable_if context").
Debug's vector → Encoder_dbg → SharedSpace (512D) → Decoder_cpp → C++ SLM injection point. No tokenization. No text generation. Pure semantic transfer.
C++ SLM receives the query PLUS Debug's semantic understanding injected at 30% blend. It "knows" what went wrong without reading a single token of Debug's explanation.
Simultaneously, C++ SLM's vector is translated to Design SLM for modernization strategy. Both specialists work in parallel, sharing semantics through the latent bridge.
Orchestrator combines outputs. Total inter-model communication: 3 vector translations (~1ms each). Zero intermediate text generation. Zero re-encoding.
The Numbers: Why This Matters
Before: Token-Based Transfer
After: Vector Channel Transfer
The 50× latency reduction is nice, but the real win is semantic preservation. When Debug SLM understands that a crash is caused by a use-after-free in a lambda capture, that nuanced understanding transfers directly to C++ SLM. No simplification, no lossy compression to natural language, no re-interpretation. The receiving model gets the actual semantic representation.
Transfer Asymmetry: A Practical Consideration
The UC Santa Cruz research found a 2.01:1 asymmetry—general-purpose models transfer better than instruction-tuned specialists. We see similar patterns:
- • C++ SLM → Debug SLM: 0.72 alignment (excellent)
- • Debug SLM → C++ SLM: 0.58 alignment (good)
- • Orchestrator → any: 0.68 alignment (very good—it's the generalist)
- • Algorithm → C++: 0.75 alignment (best pair—conceptual alignment)
We route complex queries to start with more "general" specialists when possible, taking advantage of better forward transfer.
Integration: Vector Channels + Space Converters
We already had space converters for tokenizer bridging. The vector channel system operates at a different layer—but they complement each other beautifully:
- • Bridge different tokenizer vocabularies
- • Handle domain-specific token mappings
- • Enable text-based fallback when needed
- • Work at input/output boundaries
- • Transfer semantic understanding directly
- • Bypass tokenization entirely
- • Preserve nuanced relationships
- • Work at hidden state level
Hybrid approach: Vector channels for inter-model semantic transfer; space converters for final text output and external interfaces. Best of both worlds.
The Orchestrator decides when to use each channel. Fast semantic queries go through vector channels. Complex outputs that need precise text formatting use traditional generation with space converters. The system learns which path works better for which query types.
The Future: Models That Actually Understand Each Other
Text is a terrible interface for AI-to-AI communication. It made sense when we only had one model, but multi-agent systems deserve better. The latent bridge lets our 8 specialists share meaning directly—no serialization, no information loss, no computational waste.
When Debug SLM figures out that your crash is a dangling reference from a moved-from object, that understanding should transfer instantly to C++ SLM. Not as a paragraph of text to be re-parsed, but as a semantic vector that lands directly in C++ SLM's representation of "ownership violation patterns."
That's what we built. Eight models that actually talk to each other. In math, not interpretive dance.
The future of multi-agent AI isn't more sophisticated prompt engineering between models. It's learning to share the geometry of thought directly.
References
- Yang, F.-C., & Eshraghian, J. (2025). Direct Semantic Communication Between Large Language Models via Vector Translation. arXiv:2511.03945.
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML.
- Todd, E., et al. (2024). Function Vectors in Large Language Models. arXiv:2310.15213.
Want to see vector channels in action?
Our SLM ensemble uses latent bridges for every complex query. Check out how the 8 specialists work together, or dive into our architecture deep-dives.