Why We Train Small Models That Actually Understand C++
The SLM Ensemble Approach
"GPT-4 can write hello world in any language. Our models know why your template metaprogramming is broken."
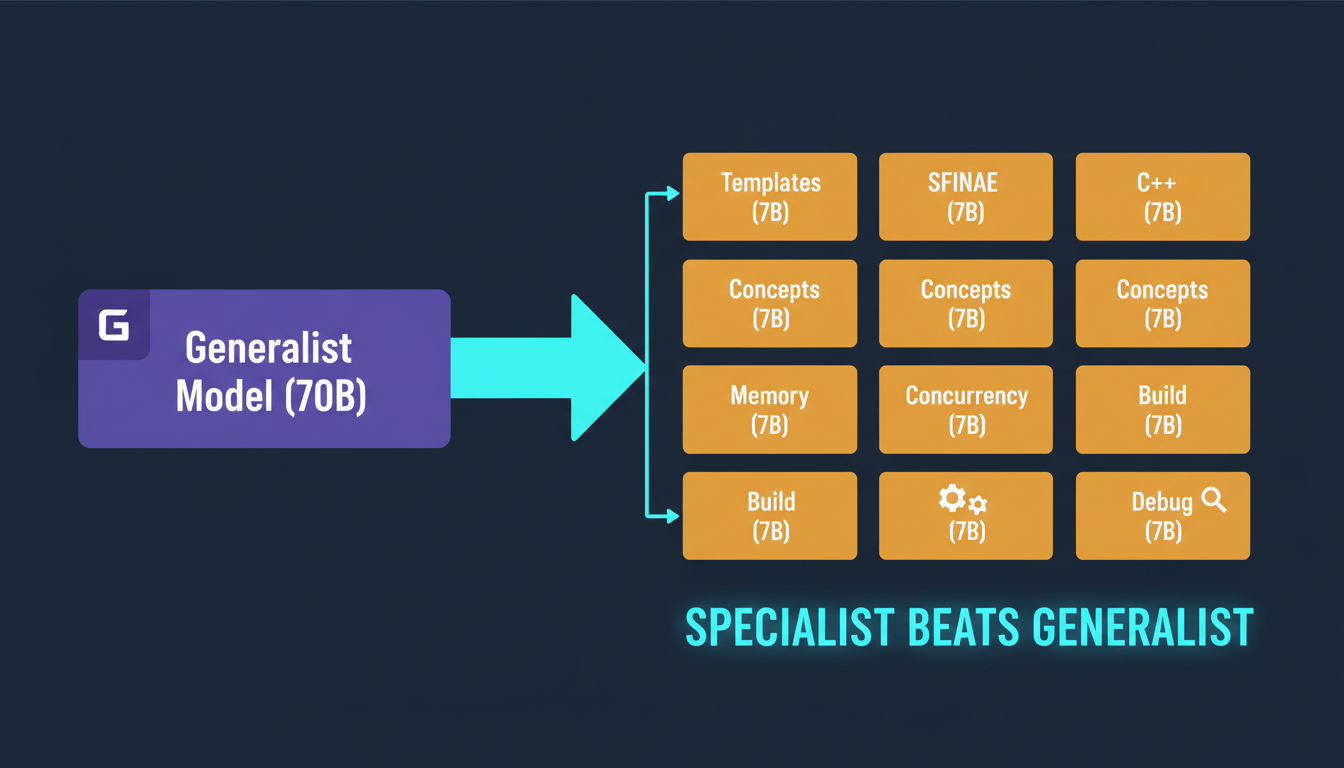
Look, I get it. When you see "7B-13B parameter models" in 2025, you probably think we've lost our minds. Everyone's racing to 70B, 175B, even 405B parameter behemoths. And yet here we are at WEB WISE HOUSE, deliberately training smaller models. Not because we can't afford the compute (though our B200s aren't exactly cheap), but because we've discovered something counterintuitive: for C++, specialists beat generalists.
This isn't about being contrarian for its own sake. After analyzing thousands of real-world C++ codebases and watching developers struggle with AI tools that treat C++ like "Python with semicolons," we realized the problem isn't model size—it's model focus.
1. Specialists vs Generalists: The Compute Economics Nobody Talks About
The Brutal Truth About 70B+ Models
A 70B model is impressive. It can switch between Python, JavaScript, Rust, Go, and yes, C++. It knows a little about everything. But here's what the benchmarks don't tell you:
- Inference cost: 70B models need serious hardware. You're looking at multiple A100s or H100s just to run inference at reasonable speed.
- Context dilution: When you train on every language under the sun, your model allocates parameters to JavaScript quirks, Python list comprehensions, Rust borrow checker hints... leaving fewer neurons for C++ template metaprogramming.
- Training efficiency: Research from CodeRL and RepoCoder shows that training with targeted retrieval and repository-level context matters more than raw model size for code completion.
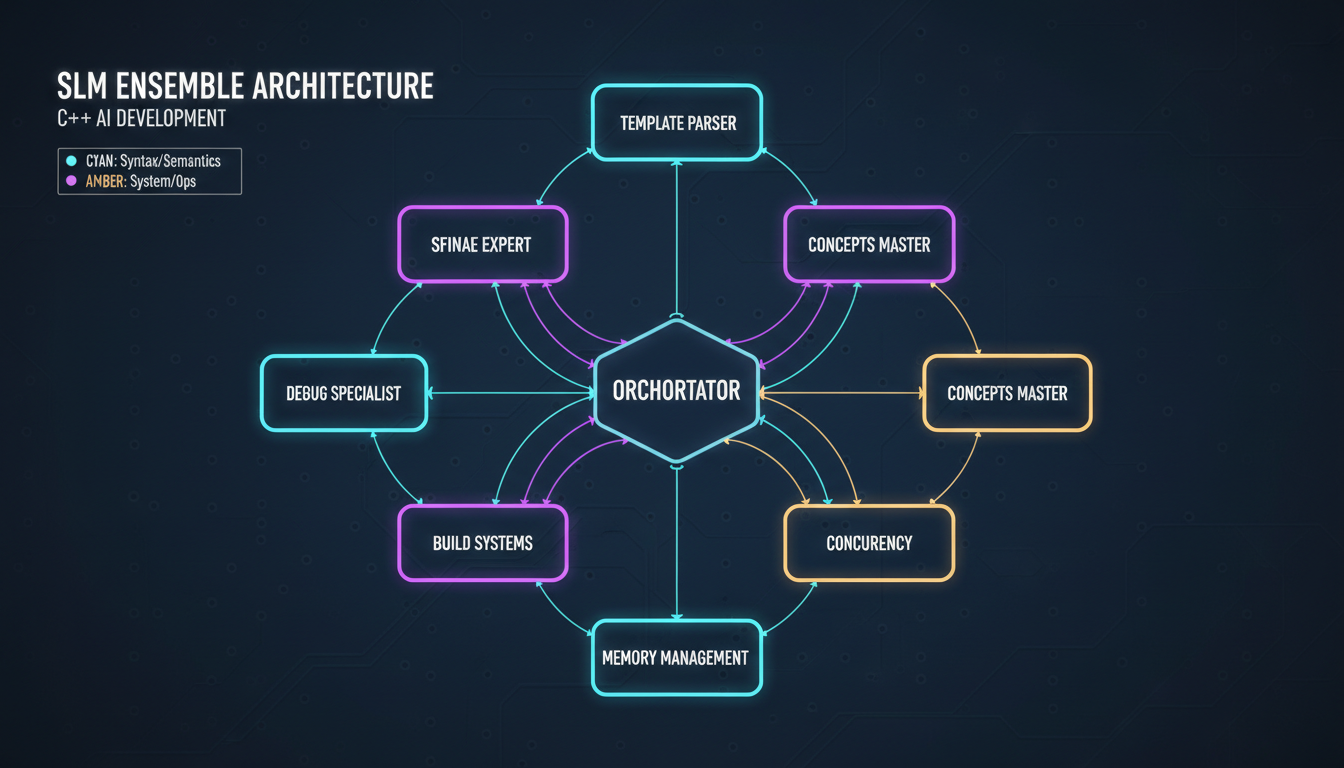
Our ensemble approach flips this on its head. Instead of one massive generalist, we train multiple 7B-13B specialists:
Template Parser Specialist
Trained exclusively on template-heavy code. Understands template template parameters, variadic templates, CTAD (Class Template Argument Deduction), and fold expressions.
SFINAE Specialist
Focused on enable_if, type traits, and the dark arts of Substitution Failure Is Not An Error. Can navigate std::enable_if_t mazes that would make a 70B model hallucinate.
Concepts Expert
Modern C++20/23 concepts and requires clauses. Understands when to use concepts vs SFINAE, and can actually explain constraint satisfaction failures.
Performance Optimizer
Trained on SIMD intrinsics, cache optimization patterns, move semantics, and perfect forwarding. Knows the difference between std::move and std::forward (and when it matters).
2. C++ Specific Training: What Makes Our Data Different
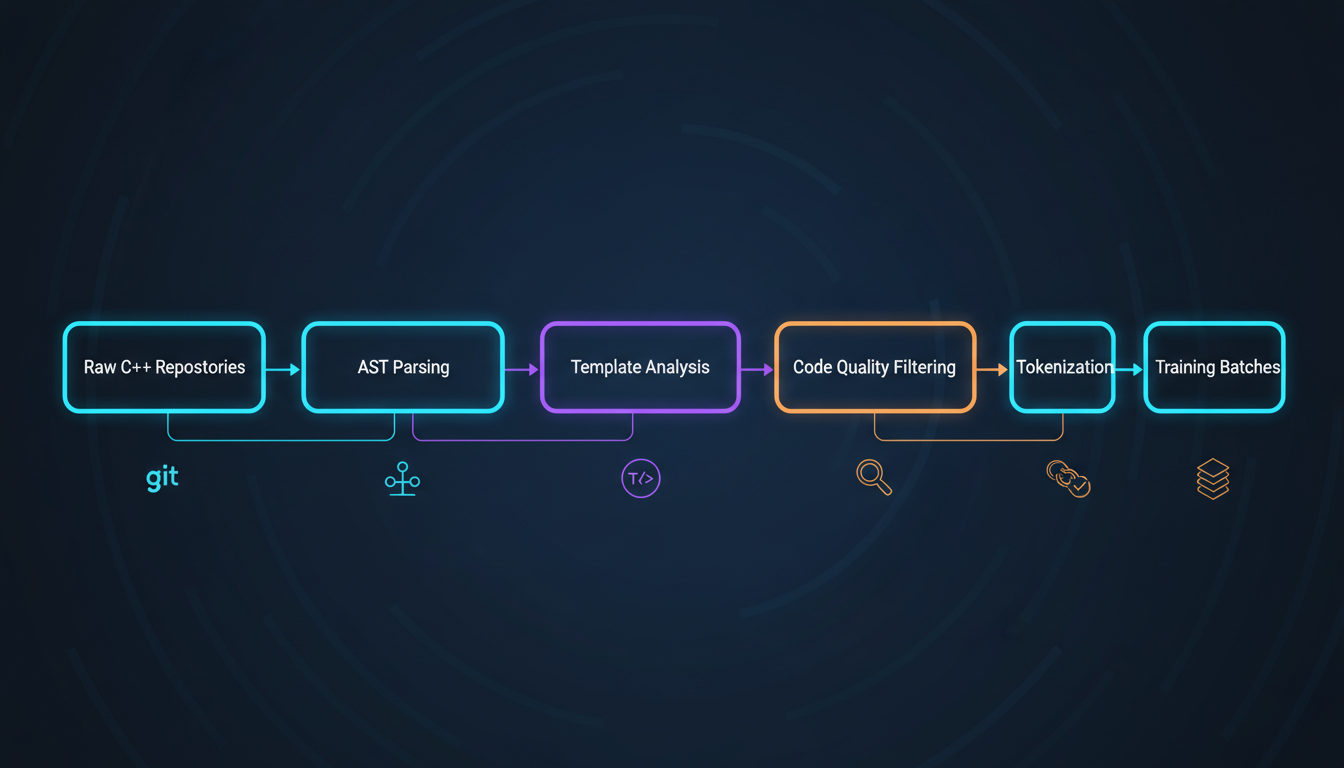
Most code models are trained on "The Stack" or similar datasets—a massive dump of GitHub repos. That's fine for general code understanding, but terrible for C++. Here's why:
The Signal-to-Noise Problem
Random GitHub C++ repos contain everything from pristine modern C++23 to ancient C++98 with macros from hell. Training on raw dumps means your model learns bad patterns alongside good ones.
We curate aggressively. Our pipeline (inspired by CrossCodeEval's repository-level understanding):
- Repository Mining: Start with high-quality C++ projects. We target libraries like Abseil, Folly, Boost, LLVM, and modern game engines. Projects with active maintenance, good test coverage, and modern C++ standards.
- Quality Filtering: Use static analysis to filter out code with:
- Undefined behavior (AddressSanitizer catches from our FAISS work are useful here)
- Deprecated patterns (raw new/delete without RAII)
- Compiler warnings on modern toolchains
- Template/Metaprogramming Extraction: Identify and oversample template-heavy code. Our Template Parser specialist needs to see thousands of variadic template examples.
- SFINAE Pattern Analysis: Extract enable_if patterns, tag dispatching, and type trait usage. Label these explicitly for targeted training.
- Concepts Validation: For C++20+ code, validate that concepts actually work (compile-time checks). We've seen too many "concept-like" templates that don't actually use requires clauses correctly.
- Cross-File Context: Following RepoCoder's insights, we maintain repository structure and cross-file dependencies. C++ code doesn't exist in isolation—headers, implementation files, and template definitions span multiple files.
Real Example: Training on Template Metaprogramming
Consider this template metaprogramming pattern from a real library:
template<typename T>
struct remove_cvref {
using type = std::remove_cv_t<std::remove_reference_t<T>>;
};
template<typename T>
using remove_cvref_t = typename remove_cvref<T>::type;
// Usage in SFINAE
template<typename T, typename U,
std::enable_if_t<std::is_same_v<
remove_cvref_t<T>, remove_cvref_t<U>
>, int> = 0>
void process(T&& t, U&& u) { /* ... */ }A generalist model sees this as "weird syntax." Our Template Parser specialist recognizes: type trait composition, alias templates, SFINAE with enable_if, and perfect forwarding. It can generate similar patterns and—crucially—explain when they'll fail.
3. The Ensemble: How Different Models Handle Different Tasks
The magic happens in the routing layer. When a developer query comes in, we don't just throw it at one model. We analyze the request and dispatch to the right specialist(s).
Query: "Complete this template function"
→ Route to Template Parser Specialist
This specialist understands template parameter deduction, return type deduction with decltype(auto), and CTAD patterns.
Query: "Why won't this enable_if compile?"
→ Route to SFINAE Specialist
Can diagnose substitution failures, suggest fixes, and often recommend migrating to concepts if you're on C++20+.
Query: "Optimize this vector processing loop"
→ Route to Performance Optimizer
Suggests SIMD intrinsics, cache-friendly data layouts, and identifies opportunities for std::execution::par (parallel algorithms).
Query: "Convert this SFINAE to C++20 concepts"
→ Route to BOTH SFINAE Specialist AND Concepts Expert
SFINAE specialist understands the original pattern, Concepts expert knows the idiomatic C++20 equivalent. The ensemble combines their outputs.
This routing isn't just keyword matching. We use a lightweight classifier (a small BERT-style model) that's been fine-tuned to recognize C++ query patterns. It considers:
- Code context (templates present? SFINAE patterns? Modern C++ features?)
- Intent keywords ("optimize," "fix," "migrate," "complete")
- Complexity indicators (template depth, constexpr usage, requires clauses)
4. Training Data Curation: Quality Over Quantity
Here's a dirty secret about code model training: most datasets are garbage. Not maliciously—just noisy. GitHub contains everything from production-grade C++ to someone's first "hello world" with memory leaks.
Our Curation Philosophy
We'd rather train on 100,000 high-quality C++ examples than 10 million random snippets. Drawing from LongCodeZip's insights on compression and relevance:
1. Compiler-Validated Code
Every training example compiles cleanly on GCC 13+, Clang 17+, and MSVC 2022. No warnings with -Wall -Wextra -pedantic.
2. Unit Test Coverage
We prioritize code that has tests. Why? Because tests reveal intent. A template function with 20 test cases teaches the model more than one without any tests. From CodeRL: unit tests provide "functional correctness" signals beyond just syntax.
3. Deduplication
GitHub is full of forks and duplicates. We use fuzzy hashing (MinHash) to detect near-duplicates and keep only canonical versions. This prevents the model from memorizing boilerplate.
4. Complexity Balancing
We maintain a distribution: 30% simple patterns (basic templates, standard library usage), 50% intermediate (SFINAE, type traits, moderate metaprogramming), 20% advanced (complex template metaprogramming, concepts with multiple constraints).
5. Modern C++ Bias
We oversample C++17/20/23 code. Yes, legacy codebases exist, but we want models that nudge developers toward modern idioms. If someone asks about a C++11 pattern, we'll also suggest the C++20 equivalent.
Data Augmentation Tricks
We don't just use code as-is. We augment:
- Identifier renaming: Prevents memorization of specific variable names. Teaches patterns, not names.
- Template parameter substitution: Replace template types with variations to increase robustness.
- Comment injection: Add explanatory comments to complex patterns (synthesized from documentation) so the model learns to explain, not just generate.
- Compiler error injection: Include examples of broken code with compiler errors. This teaches the model what NOT to do and how to diagnose issues.
5. Compute: B200 Clusters vs Local GB10 Development

Let's talk hardware. Training even 7B-13B models isn't cheap, but it's dramatically more affordable than training 70B+ monsters.
Training: B200 GPU Clusters
For training our specialist models, we use NVIDIA B200 clusters (when we can get access—these things are backordered for months). Each specialist model:
- 7B model: ~48 hours on 8x B200 GPUs
- 13B model: ~72 hours on 16x B200 GPUs
- Total training cost per specialist: $15-30K
Compare this to a 70B model which requires weeks on 64+ GPUs at $200K+ per training run. We can train 6 specialists for the cost of one generalist.
Inference: GB10 Local Deployment
For development and testing, we deploy on GB10 GPUs (NVIDIA's latest gaming/workstation cards). Our ensemble setup:
- Each 7B specialist fits comfortably in 16GB VRAM
- 13B models need 24GB (GB10 Pro)
- Inference latency: ~50-100ms per query
- Batch processing: 10-20 queries/second
A single developer can run the entire ensemble on a workstation with 2-3 GB10 GPUs. Try doing that with a 70B model (hint: you can't).
Optimization Tricks
To squeeze maximum performance from smaller models, we employ several techniques:
Flash Attention 2
Reduces memory usage and speeds up attention computation. Critical for fitting 13B models in 24GB VRAM during training.
Quantization-Aware Training
We train with INT8 quantization in mind, so deployment can use 8-bit inference without significant accuracy loss. Halves memory requirements.
KV Cache Sharing
When routing queries through the ensemble, we share KV cache for common prefixes. If two specialists see the same context, we cache once and reuse.
Speculative Decoding
Use a tiny draft model (1B parameters) to propose tokens, then verify with the specialist. Speeds up generation by 2-3x for simple completions.
6. Our Specific Training Pipeline
Training isn't just "throw data at GPU and wait." Our pipeline incorporates lessons from recent research:
Stage 1: Pretraining (Base Model)
We start with a base 7B decoder-only transformer (similar to LLaMA architecture). Pretrain on:
- 10B tokens of general C++ code (filtered from The Stack)
- Next-token prediction objective
- Learning rate: 3e-4, batch size 2M tokens, 100K steps
- Cosine decay schedule with 10% warmup
Stage 2: Domain Specialization
Fork the base model into specialists. Each gets continued pretraining on its domain:
- Template Parser: 2B tokens of template-heavy code
- SFINAE Specialist: 1.5B tokens of SFINAE patterns and type traits
- Concepts Expert: 1B tokens of C++20/23 code with concepts
- Performance Optimizer: 1B tokens of optimized code with profiling annotations
Learning rate: 1e-4 (lower to avoid catastrophic forgetting), 50K steps per specialist.
Stage 3: Instruction Tuning
Fine-tune each specialist on instruction-following tasks. Inspired by CodeRL's actor-critic approach:
- 100K instruction-response pairs per specialist
- Tasks: code completion, bug fixing, explanation, migration
- Reinforcement learning from compiler feedback (compiles? tests pass?)
- PPO (Proximal Policy Optimization) with KL penalty to prevent drift
Stage 4: Cross-File Context Training
This is where RepoCoder and CrossCodeEval insights shine. C++ code needs repository-level understanding:
- Train on multi-file contexts (headers + implementation)
- Include cross-file dependencies (included headers, linked definitions)
- Retrieval-augmented generation: fetch relevant files when completing code
- Context window: 16K tokens (enough for multiple files)
Stage 5: Ensemble Training
Train the router and calibrate specialist outputs:
- Router: small BERT model (110M params) trained to classify queries
- Calibration: adjust confidence scores so ensemble voting works well
- Multi-task examples: train router to dispatch to multiple specialists when needed
- A/B testing on held-out queries to validate routing accuracy
The Bottom Line
Training 7B-13B specialists isn't just a cost-saving measure—it's a better architecture for C++. By focusing each model on a specific domain, we achieve:
- Better accuracy on specialized tasks (templates, SFINAE, concepts)
- Lower inference costs (run on GB10s instead of needing A100 clusters)
- Faster iteration (training 6 specialists in parallel vs one huge model)
- Explainability (we know which model made which decision)
When the next 500B parameter model drops, everyone will ooh and ahh. And we'll keep training our specialists, because for C++, focus beats scale.
Want to try our SLM Ensemble?
Our models are available through the CppCode.online API. Enterprise licenses available for on-premises deployment.
Explore SLM Ensemble →References
[1] Le, H., Wang, Y., et al. (2022). CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning. Uses actor-critic RL with unit test feedback for functional correctness.
[2] Zhang, F., Chen, B., et al. (2023). RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. Demonstrates importance of repository context and cross-file dependencies.
[3] Ding, Y., Wang, Z., et al. (2023). CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. Shows that cross-file context significantly improves code completion accuracy.
[4] Shi, Y., Qian, Y., et al. (2025). LongCodeZip: Compress Long Context for Code Language Models. Introduces perplexity-based compression for efficient long-context code understanding.