The 4-Bit Miracle: How NVFP4 Squeezes 16-Bit Intelligence into 4-Bit Memory
Or: How We Learned to Stop Worrying and Love Aggressive Quantization
"Only 16 numbers? That's fewer than I have socks! And somehow, it works."
Imagine compressing a 4K movie into GIF size with no quality loss. That's essentially what NVFP4 does for neural networks. It sounds impossible—how do you fit 65,536 possible values (FP16) into just 16 buckets (FP4)? The answer: you don't. You get clever about what matters.
After months of experimentation with our SLM ensemble (7 specialized models, 4B-8B parameters each), we've become true believers. NVFP4 isn't just a memory trick—it's what makes our entire architecture possible. Without it, we'd need 100+ GB of VRAM. With it? 28 GB. That's the difference between "needs a server rack" and "runs on a single GPU."
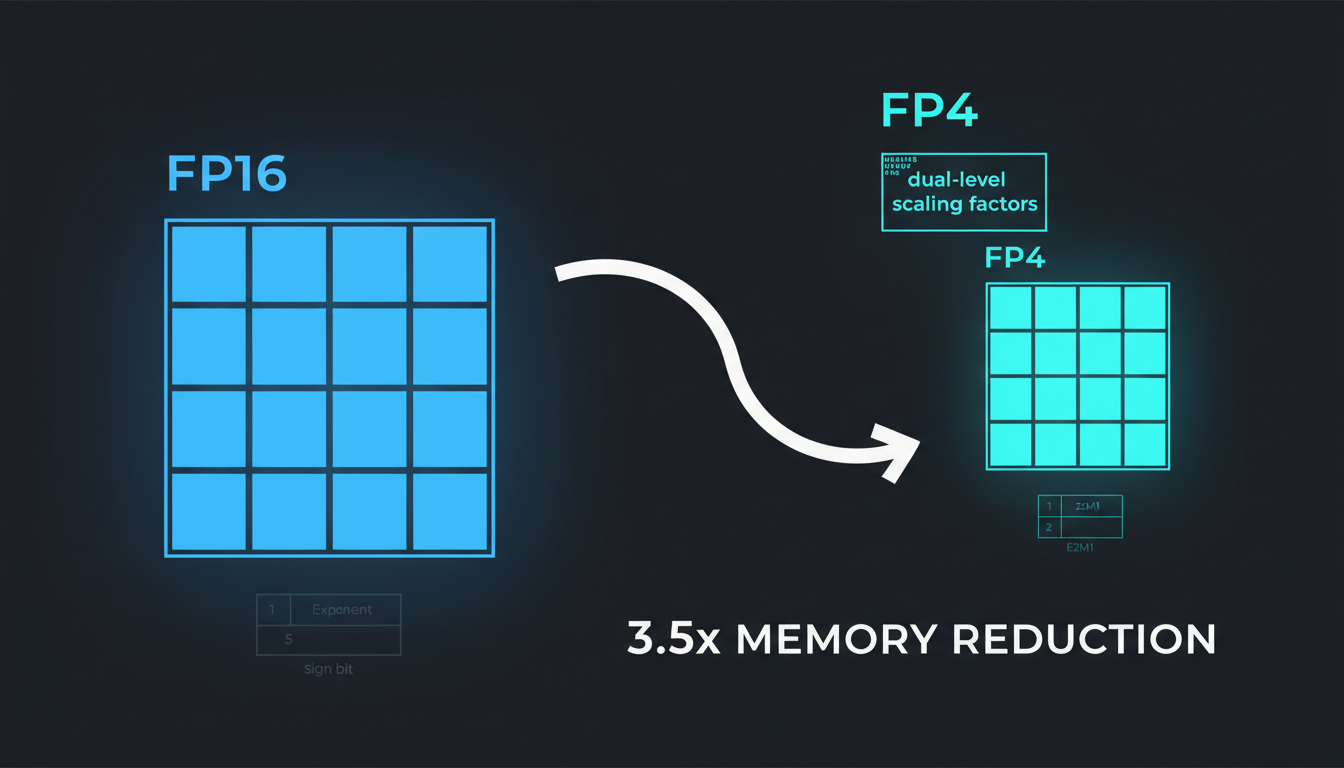
1. The E2M1 Format: 4 Bits of Magic
NVFP4 uses the E2M1 format: 1 sign bit, 2 exponent bits, 1 mantissa bit. That's it. The entire universe of representable values is: ±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, ±6.
The 16 Values of NVFP4
That's your entire numerical vocabulary. Fewer values than most people have browser tabs open.
"But wait," you're thinking, "neural network weights have way more variety than 16 values!" You're right. That's where the magic happens: dual-level scaling.
2. Dual-Level Scaling: The Real Innovation
Here's the insight that makes NVFP4 work: neural network weights cluster. They don't spread uniformly across all possible values—they congregate in neighborhoods. NVFP4 exploits this by using two levels of scaling:
Level 1: Micro-Block Scaling
Every 16 consecutive weights share an FP8 E4M3 scale factor. Think of it as each neighborhood having its own "zoom level."
This alone reduces quantization error by 88% compared to MXFP4's power-of-two scaling.
Level 2: Tensor-Wide Scaling
The entire tensor also gets a single FP32 scale factor. This handles the global dynamic range that micro-blocks can't cover.
Prevents overflow when local scales aren't enough for outliers.
It's like using scientific notation for both 0.0001 and 10,000—the same 16 base values can represent wildly different magnitudes depending on the scale. The effective storage cost is 4.5 bits per value (4-bit value + 1/16th of an FP8 scale + amortized FP32 scale), but the accuracy approaches FP8.
The Analogy
Think of NVFP4 as MP3 compression for neural networks. MP3 doesn't store every sound wave—it stores what your ears actually perceive. Similarly, NVFP4 doesn't preserve every weight precisely—it preserves what the network actually uses for computation. We throw away what the model "can't hear."

3. The Numbers That Made Us Believers
| Metric | FP16 | FP8 | NVFP4 |
|---|---|---|---|
| Memory per 7B Model | 14 GB | 7 GB | 4 GB |
| Throughput (vs FP16) | 1x | 2x | 4x |
| Accuracy Loss | 0% | <2% | <1% |
| 7-Model Ensemble Total | ~100 GB | ~50 GB | ~28 GB |
Read that last row again. Our entire 7-model SLM ensemble—C++, CMake, Debug, Shell, Orchestration, Design, and Review specialists—fits in 28 GB. That's less than a single 70B generalist model in FP16. This isn't a minor optimization; it's what makes the architecture economically viable.
DeepSeek-R1 Results (FP8 → NVFP4)
Yes, you read that right. Some benchmarks actually improve with quantization. We don't fully understand why—possibly implicit regularization from the discretization—but we'll take it.
4. Why 16-Element Blocks Beat 32-Element Blocks
NVIDIA's competing format, MXFP4, uses 32-element blocks with E8M0 (power-of-two) scaling. Sounds reasonable, right? Larger blocks = less overhead. But here's the catch: outliers.
When one value in your block is an outlier, the entire block's scale must accommodate it. With 32 elements, you have twice the chance of an outlier dominating your quantization. NVFP4's 16-element blocks give each local neighborhood more autonomy.
The 36% Token Penalty
In a controlled experiment, an 8B model trained with MXFP4 needed 36% more training tokens to match the performance of the same model trained with NVFP4. That's not a rounding error—that's a significant compute tax.
Smaller blocks + fractional scales (E4M3 instead of E8M0) = 88% lower quantization error.
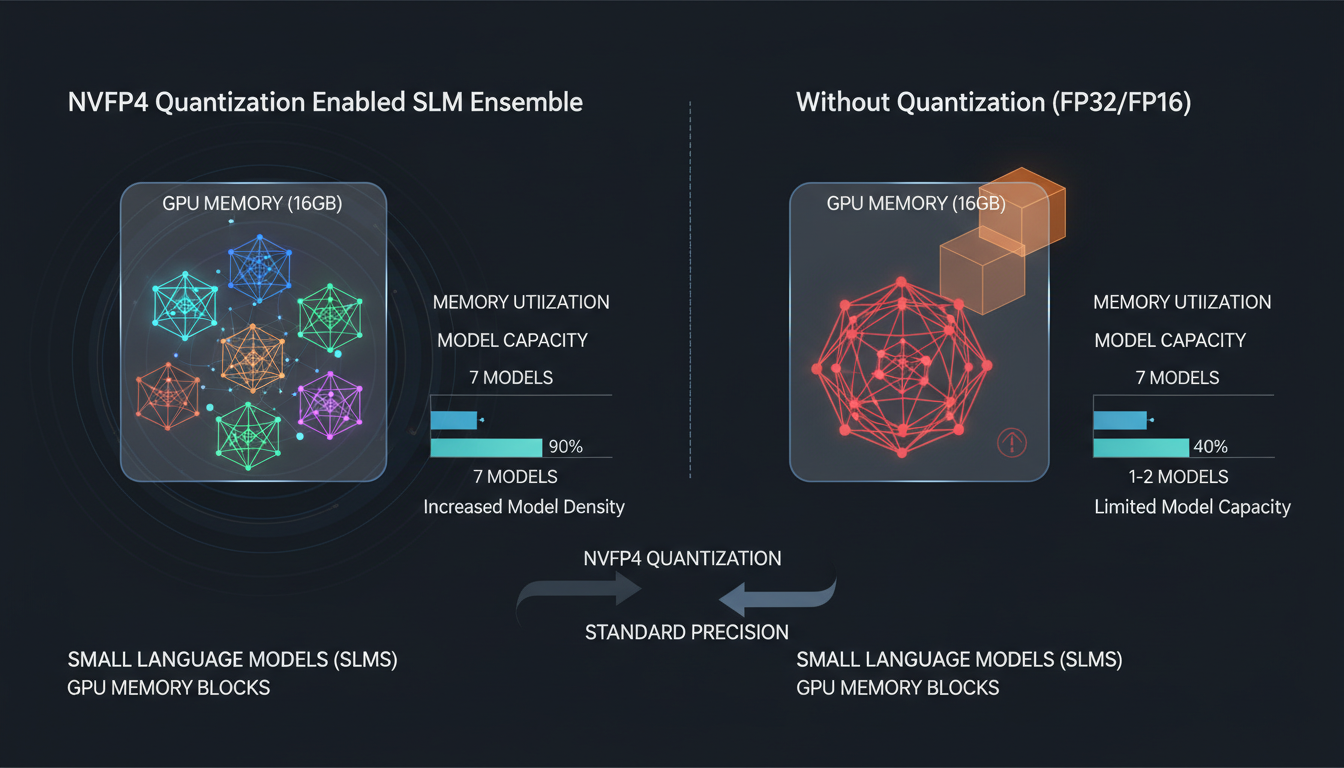
5. What This Means for Our Architecture
Our SLM ensemble has 7 specialized models ranging from 4B to 8B parameters each. Here's what NVFP4 enables:
Single-GPU Deployment
All 8 models fit on a GB200 with ~164 GB to spare for KV cache and activations. No multi-GPU coordination overhead.
Fast Model Switching
Sub-10ms model swaps because all models are resident in memory. The orchestrator can route to specialists instantly.
~50% Training Cost Reduction
NVFP4 training achieves ~2x throughput. For 8 models × 150B tokens each, that's a massive compute savings.
Space Converters Enabled
Our mixed tokenizer strategy—with space converters between SLMs—benefits from NVFP4's low latency for real-time conversion.
The first time you load 8 models in the memory budget of 2, you'll feel like you're breaking physics. You're not—you're just exploiting the surprising compressibility of neural network weights.
6. Getting Started with NVFP4
# Post-Training Quantization with TensorRT Model Optimizer
import modelopt.torch.quantization as mtq
# Quantize to NVFP4 with 512 calibration samples
model = mtq.quantize(
model,
mtq.NVFP4_DEFAULT_CFG,
forward_loop # Runs calibration data through model
)
# Export for deployment
mte.export_hf_checkpoint(model, "./slm-cpp-8b-nvfp4")The Catch: Hardware Requirements
NVFP4's magic requires Blackwell GPUs (GB100, GB200, RTX 50 series) for native acceleration. On older hardware, you can still use the format, but it dequantizes to FP16 for computation— losing most of the speed benefit.
Memory savings still apply regardless of GPU generation, but the 4x throughput improvement is Blackwell-only.
If your accuracy drops more than 5% after quantization, don't panic—it means your calibration data wasn't representative. Try increasing samples from 512 to 1024, or consider Quantization-Aware Training (QAT) for models under 7B parameters where PTQ struggles.
The Bottom Line
NVFP4 isn't just another quantization format—it's what makes ambitious architectures like ours economically viable. The combination of 3.5x memory reduction, 4x throughput improvement, and <1% accuracy loss fundamentally changes what's possible on a single GPU.
We went from "our ensemble needs a server rack" to "our ensemble runs on one chip." That's not incremental improvement—that's a phase transition.
"There's something profound about the fact that intelligence compresses so well. We're not just optimizing memory—we're learning which dimensions of the weight space actually matter."
Next up: how we combined Mamba 3 and Transformers into a hybrid architecture that everyone said wouldn't work. (Spoiler: it works.)