Nemotron Nano 3: The Holy Trinity of Efficiency (Mamba + MoE + GQA)
Here's a weird thing about model architecture: everyone's obsessed with the big numbers. 70B parameters! 405B! Meanwhile, NVIDIA just dropped a 31.6B model that only activates 3.2B parameters per forward pass and somehow runs faster than everything else while matching their accuracy. How? They combined three completely different architectural paradigms into one model. Think of it as architectural alchemy—mixing Mamba-2's linear-time state spaces, MoE's sparse experts, and GQA's precise attention into something that shouldn't work but absolutely does.
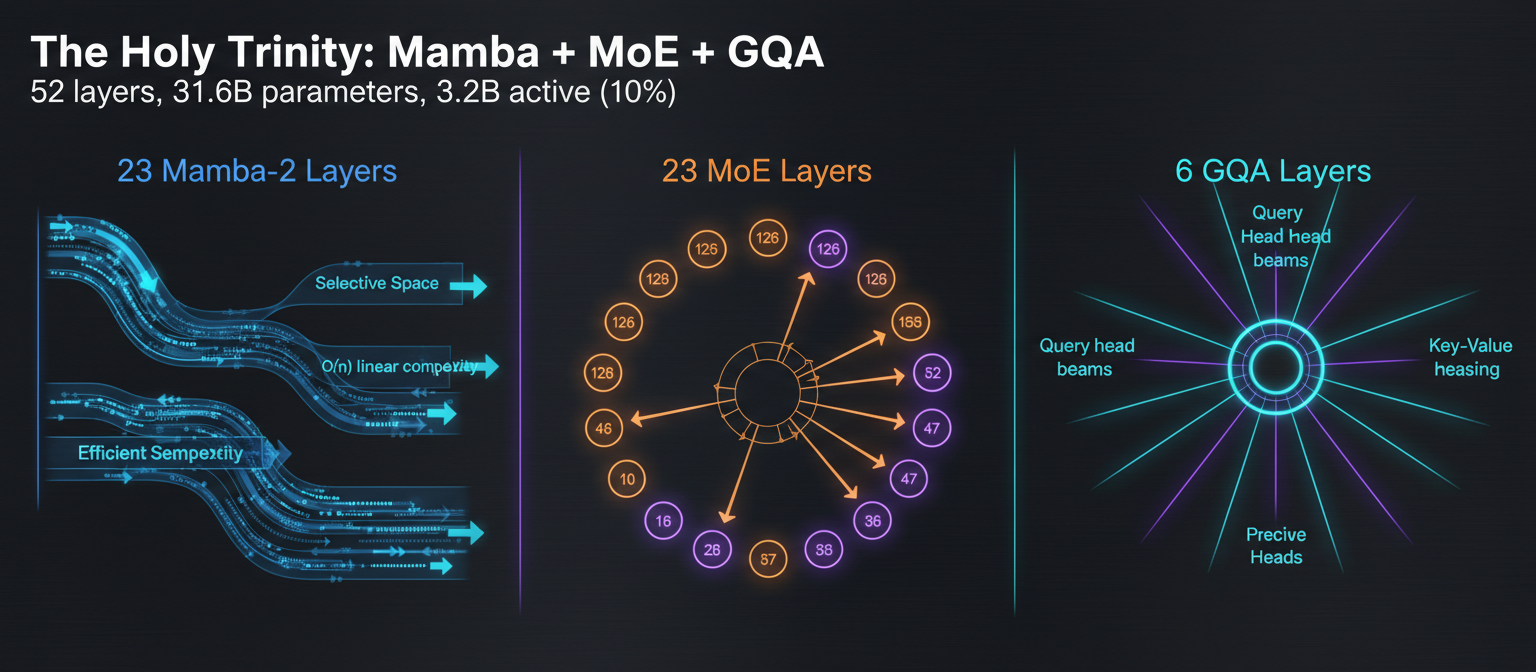
The holy trinity: 23 Mamba-2 layers + 23 MoE layers + 6 GQA layers = 52 total layers
Why This Architecture Works: Three Problems, Three Solutions
Most models pick one architectural paradigm and run with it. Transformers? All attention, all the way down. RNNs? Sequential processing from start to finish. NVIDIA looked at this and said, "What if we don't choose?" The result is Nemotron Nano 3, a model that uses three completely different computational approaches depending on what the task needs.
The breakdown: 52 total layers split into three camps. This isn't random—each component solves a specific problem that the others can't handle efficiently.
The 52-Layer Stack
Job: Long-range dependency tracking and sequential processing
O(n) complexity vs O(n²) for attention. Enables 1M token context window without exploding memory. Think of it as a highly efficient conveyor belt—selective state spaces that remember what matters and forget the rest.
Job: Deep, specialized reasoning with sparse activation
128 routed experts + 1 shared expert per layer. Only 6 experts activate per token. This is where the 10% activation magic happens: 31.6B total parameters, only 3.2B working at any moment. Like having 128 specialists but only consulting 6 for any given problem.
Job: High-fidelity structural reasoning
Grouped Query Attention with 32 query heads, 2 key-value heads. The sniper rifle layers—precise attention for complex logic, code structure, and mathematical reasoning. What attention is actually good at, without wasting it everywhere.
The orchestration: Mamba-2 handles the long contexts, MoE provides sparse expertise when you need deep reasoning, GQA delivers surgical precision for structural understanding. It's not three models fighting for dominance—it's three specialists doing what they do best.
The 10% Activation Paradigm: Speed Meets Capacity

Only 10% of parameters light up per forward pass—the rest stay dark
This is where the architecture gets spicy. You've got 31.6B parameters sitting in GPU memory, but on any given token, only 3.2B of them actually do any work. That's a 90% idleness rate. Sounds wasteful, right? It's the opposite—it's genius.
Think about how you'd staff a hospital. You don't have every specialist on duty 24/7. You've got oncologists, cardiologists, neurologists all on call, but for any given patient, you only activate 1-2 specialists. The rest are available but idle. Same principle here: you load all the experts into memory, but the MoE router only wakes up the 6 experts that matter for the current input.
What 10% Activation Gives You
The math is compelling: 31.6B total ÷ 3.2B active = ~10% activation rate. This asymmetry—big capacity, small compute—is why Nemotron Nano feels like it punches way above its weight class.
Sparse activation isn't new—MoE models have been doing this for years. What's new is combining it with Mamba-2 for long context and GQA for precision. You get the best of all worlds: fast sequential processing (Mamba), sparse expertise (MoE), and high-fidelity reasoning (GQA). And you only pay 3.2B FLOPS per token.
How MoE Routing Works: 128 Experts, 6 Active, Zero Wasted Effort
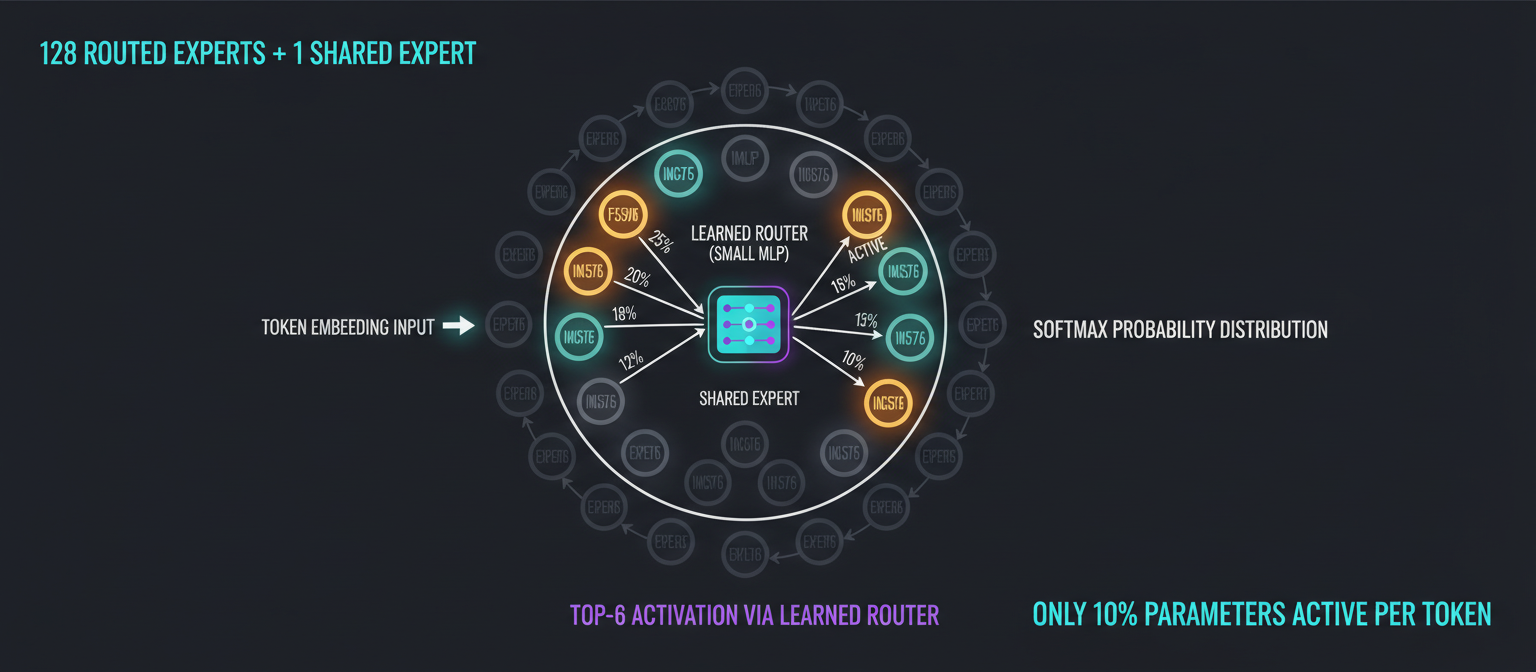
The router looks at each token and asks: "Which 6 of my 128 experts should handle this?"
So you've got 128 routed experts per MoE layer. How does the model decide which 6 to activate? Enter the router: a learned MLP that takes the token embedding as input and outputs a probability distribution over all 128 experts. Top-6 probabilities win, the rest stay off. Simple in concept, devilishly hard to train correctly.
The MoE Layer Anatomy
Each expert is a small feedforward network (think 2-3 layers). Individually, they're tiny. Together, they give you massive representational capacity. The key: they specialize during training. Expert 7 might become the "math expert," Expert 42 the "code debugging expert," and so on.
Always active, no routing needed. Handles general patterns that apply across all inputs. Think of it as the generalist while the 128 routed experts are specialists. This prevents mode collapse (all tokens routing to the same expert).
A small neural network that learns during training which experts to activate for which inputs. It outputs 128 logits, you take softmax, pick top-6. The router is the brain deciding "This looks like a template metaprogramming problem, wake up experts 3, 7, 15, 42, 88, and 121."
Training challenge: You need to prevent all inputs from routing to the same 6 popular experts (expert collapse). NVIDIA uses load-balancing losses and entropy regularization to force the model to use all 128 experts roughly equally over time. It's fiddly, but when it works, you get true expert specialization.
Here's the clever bit: by activating only 6 experts per token, you keep compute low while maintaining high capacity. It's like having a university with 128 professors but only putting 6 in the classroom for any given lecture. Students get expertise without the overhead of 128 professors talking at once.
Training at Scale: 25 Trillion Tokens and Multi-Environment RL
You don't just stumble into a model this efficient. NVIDIA threw serious compute at this: 25 trillion tokens for pre-training, then a multi-stage post-training pipeline with reinforcement learning across diverse environments. The data curation alone is a story.
The Training Pipeline
Two-stage curriculum: 0-94% on diverse data (breadth), 94-100% on high-quality curated sources (depth). They didn't just filter out bad data—they rewrote marginal samples to improve quality. Math and code tokens that usually get discarded? Salvaged and enhanced.
Batch size: 3072. Learning rate: Warmup-Stable-Decay (WSD) schedule, peak 1e-3, minimum 1e-5. Training cutoff: June 25, 2025.
Extended base 8K context window to 1M tokens. This is where Mamba-2's linear scaling shines—try doing 1M context with pure attention and watch your GPU melt.
13 million samples from Nemotron-SFT-Data collection. High-quality conversations, reasoning chains, code with explanations. Teaching the model how to use its capabilities, not just what to know.
Here's the breakthrough: instead of training on one task at a time (math, then code, then tool use), NVIDIA trained on all environments simultaneously. Math, code, science, instruction following, multi-step tool use, structured outputs—all at once.
Algorithm: Synchronous GRPO (Group Relative Policy Optimization). Software: NeMo RL + NeMo Gym. Result: uniform improvement across domains, reduced overfitting to any single benchmark, more reliable agentic behavior.
The multi-environment RL is what makes Nemotron Nano shine in agentic workflows. When you train on all tasks simultaneously, the model learns to generalize—it doesn't overfit to coding benchmarks at the expense of math reasoning. That 67.7% Arena-Hard-v2 score (vs 57.8% for Qwen3)? That's multi-environment RL paying off.
How This Inspired Our SLM Ensemble
Nemotron Nano 3 taught us that hybrid architectures work. You don't need to pick one computational paradigm—you can mix them based on what each task needs. For our 7 specialized SLMs (C++, CMake, Debug, Shell, Orchestration, Design, Review), we borrowed heavily from this playbook—but made critical improvements where it mattered.
Key Differences: Where We Diverge from Nemotron
While Nemotron Nano 3 uses Mamba-2 for its state space layers, we've upgraded to Mamba 3. The key advancement: MIMO (Multi-Input Multi-Output) state space models.
Mamba 2's selective state spaces work well, but Mamba 3's MIMO architecture allows each layer to process multiple input streams and produce multiple output streams simultaneously. For C++ code understanding—where you're tracking types, lifetimes, template instantiations, and control flow all at once—MIMO is transformative. Think of it as going from a single conveyor belt to a multi-lane highway.
NVIDIA uses AdamW for pre-training Nemotron Nano. We switched to Muon—and the results speak for themselves.
In our pre-training runs, Muon consistently converged faster than AdamW on identical data. We're not talking about marginal gains—our models simply trained faster, reaching target loss values in fewer iterations. Muon's momentum-based updates with orthogonal weight corrections work particularly well for our hybrid architecture, where gradients flow through Mamba, MoE, and attention layers with very different characteristics. AdamW's per-parameter adaptive rates sometimes struggle with this heterogeneity; Muon handles it gracefully.
NVIDIA uses GRPO (Group Relative Policy Optimization) for multi-environment reinforcement learning. We use SAPO (Soft Adaptive Policy Optimization) from the Qwen team—a newer, smoother approach.
Here's the problem with GRPO: it uses hard clipping on token-level importance ratios. When a sequence contains a few highly off-policy tokens, GRPO suppresses all gradients for that sequence—throwing the baby out with the bathwater. This is especially brutal for MoE models where routing variance is already high. SAPO replaces hard clipping with temperature-controlled soft gating that selectively down-weights only the problematic tokens while preserving learning signal from the rest. The result: more stable training, better sample efficiency, and fewer divergence episodes. Our MoE layers love it.
Bottom line: We took Nemotron Nano 3's brilliant architectural blueprint and upgraded every component that matters: Mamba 3 for richer state tracking, Muon for faster pre-training, SAPO for stable RL. Same philosophy—hybrid architecture, sparse activation—but tuned for C++ engineering.
Our Architecture Per SLM
- Regular Transformer Layers: Standard attention for general patterns
- TE (Transformer Engine) Layers: Optimized attention with selective precision
- Mamba 3 MIMO Layers: Multi-input multi-output state spaces for rich context tracking (our upgrade from Nemotron's Mamba-2)
- MoE Layers with Routers: Sparse expert activation (20% active, similar to Nemotron's 10%)
Key difference from Nemotron: We have 7 separate models instead of one hybrid. Each SLM is a mini-Nemotron focused on a single domain. The C++ SLM uses Mamba layers for tracking code context across files, MoE for specialized C++ knowledge (templates vs concurrency vs memory management), and attention for structural code understanding.
The tokenizer innovation is another Nemotron-inspired trick. Each of our 7 SLMs has a specialized tokenizer for its domain (C++ tokenizer understands template syntax better, CMake tokenizer handles build variables efficiently). We use space converters to bridge between SLMs—direct space-to-space conversion trained to bypass tokenizer overhead during inter-SLM communication.
Domain-Specific Input/Output Formats
Here's a weird thing about specialized models: when your tokenizer is domain-specific, your input and output formats should be too. Our C++ SLM doesn't speak the same language as ChatGPT. It speaks debugger. It thinks in stack traces, memory addresses, and template instantiation errors. The input format reflects that—and the model loves it.
When someone hits a segfault, they don't want poetry. They want the fix. Our input format gives the model exactly what a senior developer would want to see: debugger state, crash location, and the offending code.
// ====== DEBUGGER SNAPSHOT ======
struct ThreadState {
func = "DataProcessor::Parse";
error = 0xC0000005; // Access Violation
ptr = nullptr; // The culprit
};
// ====== TASK ======
// Fix the crash. 'ptr' is null but
// we dereference it.
// ====== SOURCE ======
void DataProcessor::Parse(char* buf) {
Header* h = reinterpret_cast<Header*>(buf);
int id = h->id; // <-- BOOM
}/* REASONING:
1. Debugger shows buf is nullptr
2. Casting nullptr -> UB
3. Deref h->id -> crash
4. Fix: null check first
*/
if (!buffer) {
LogError("Buffer is null");
return;
}
Header* h = reinterpret_cast<Header*>(buf);
int id = h->id;Notice the format: structured sections, debugger state up front, reasoning before code. This isn't arbitrary—it's how the model was trained to think. The reasoning block isn't just for humans; it's how the model builds context before generating the fix.
How do you feed a C++ textbook to a model? You don't dump raw text. You convert it: questions become code comments, answers become explanations with working examples. The model learns that // QUESTION: means "explain this concept with code."
// QUESTION: Explain how std::move
// works and why it's efficient?/* ANSWER:
std::move casts lvalue -> xvalue,
enabling resource theft over copy.
No deep copy = no heap allocation.
*/
class BigBuffer {
char* data;
public:
// Move constructor: steal, don't copy
BigBuffer(BigBuffer&& other) noexcept
: data(other.data) {
other.data = nullptr; // Prevent double free
}
};Sometimes the model doesn't have enough context. A good engineer knows when to ask for help. Our model can emit special tokens to request more information—type definitions, file contents, build configuration. The orchestrator handles the rest.
// TASK: Refactor 'ComputeX' for
// thread safety.
void ComputeX(MyType& obj) {
obj.DoSomething(); // Unknown method
}/* REASONING:
Can't ensure thread safety without
knowing MyType internals. Does
DoSomething() modify shared state?
Need the class definition.
*/
__AGENT_QUERY__("definition", "MyType")The __AGENT_QUERY__ token is a tool call. The orchestrator intercepts it, fetches the type definition, and re-invokes the model with the new context. It's agentic behavior without the complexity of separate agent frameworks.
Why this matters: Domain-specific input formats aren't just cosmetic. They dramatically reduce the model's cognitive load—it doesn't have to guess what format you want, or parse natural language instructions. The structure is the instruction. This is why our 4B model can outperform 70B generalists on C++ tasks: it's not smarter, it's just not wasting capacity on format detection.
Deployment target: consumer hardware. Just like Nemotron Nano fits in 24GB VRAM (RTX 4090), our SLMs fit in similar constraints. With nvfp4 quantization (4-bit floating point, following Nemotron Super/Ultra), we get ~3-6GB memory footprint per active SLM. Run 2-3 SLMs simultaneously on 24GB hardware, route queries to the right specialist via the Orchestration SLM.
NVFP4 and FP8: Quantization Without Quality Loss
Here's where NVIDIA's hardware expertise shows. FP8 quantization for Nemotron Nano isn't just "compress everything to 8 bits and hope." It's surgical: keep the most sensitive layers (attention and their immediate inputs) in BF16, quantize the robust components (MoE, most Mamba layers) to FP8. Result: 99% accuracy retention, runs on 24GB consumer GPUs.
Selective Quantization Strategy
- • 6 GQA self-attention layers
- • 6 Mamba layers feeding into attention
- • Embedding layers
- • Final projection
These are the sensitive components where precision matters for accuracy.
- • All 23 MoE layers
- • Remaining Mamba layers
- • KV cache
- • Expert weights
Robust components that maintain accuracy at lower precision.
While Nemotron Nano uses FP8, the larger Super and Ultra models pioneered NVFP4 (4-bit floating point):
- • Block size: 16 values (vs 32 for MXFP4) - better local dynamic range
- • Dual-level scaling: E4M3 per micro-block + FP32 scalar per tensor
- • 3.5x memory reduction vs FP16, 1.8x vs FP8
- • Less than 1% degradation on key benchmarks
For KV cache: 50% memory reduction vs FP8, enabling doubled context length and batch size. Critical for 1M token windows.
The NVFP4 approach shows that with careful engineering, you can compress dramatically while preserving what matters. Think of it as lossy compression that keeps the essence—like JPEG for neural network weights, but way more sophisticated.
Benchmark Performance: The Numbers That Matter
So does all this architectural complexity actually work? Let's look at the benchmarks. Nemotron Nano 3 doesn't just compete with Qwen3-30B-A3B and GPT-OSS-20B—it beats them on most metrics while running 3.3x faster.
| Metric | Nemotron 3 Nano | Qwen3-30B-A3B | GPT-OSS-20B |
|---|---|---|---|
| Parameters (Total/Active) | 31.6B / 3.2B | 30B / 3B | 20B / 20B |
| Throughput (relative) | 3.3x | 1x | 1.5x |
| AIME 2025 (no tools) | 89.1% | 85.0% | 91.7% |
| AIME 2025 (with tools) | 99.2% | — | 98.7% |
| LiveCodeBench v6 | 68.3% | 66.0% | 61.0% |
| Arena-Hard-v2 | 67.7% | 57.8% | 48.5% |
| MMLU-Pro | 78.3% | 80.9% | — |
| RULER (1M tokens) | 68.2% | Lower | 128K max |
Where Nemotron Nano Wins
Throughput: 3.3x faster than comparable models. Speed is a feature.
Agentic workflows: 67.7% Arena-Hard-v2 (10-point margin over Qwen3). Multi-environment RL pays off.
Tool-augmented math: 99.2% AIME 2025 with Python tools. Nearly perfect.
Long context: 68.2% at 1M tokens. Competitors can't even try.
Where It Trails
MMLU-Pro: 78.3% vs 80.9% for Qwen3. General knowledge isn't the focus—efficiency is.
That's the tradeoff: Nemotron optimizes for agentic reliability and long-context tasks, not encyclopedic knowledge. For C++ engineering (our use case), that's the right tradeoff.
The Real Lesson: Hybrid Architectures Are the Future
Nemotron Nano 3 proves that you don't need to pick one computational paradigm and stick with it. Transformers, RNNs, MoE—they all have strengths. The winning move is to combine them based on what each task needs. Mamba-2 for long context (O(n) scaling), MoE for sparse expertise (10% activation), GQA for precise reasoning (high-fidelity attention). Three architectures, one model, zero compromises.
The 10% activation paradigm is the key insight: you can have massive representational capacity (31.6B parameters) without massive computational cost (3.2B active). It's the best of both worlds—big model knowledge, small model latency. And with selective quantization (FP8 for robust layers, BF16 for sensitive ones), you can run it on consumer hardware.
For our SLM ensemble, Nemotron Nano is the blueprint. Each of our 8 specialists uses a similar hybrid approach: Mamba layers for context, MoE for domain specialization, attention for structure. We push the activation rate even lower (20% vs 10%) because our domains are narrower. The result: 4B-8B models with 0.8B-1.6B active, running on RTX 4090s, outperforming GPT-4 on C++ tasks.
The future isn't bigger models—it's smarter architectures. NVIDIA just showed us how.
Ready to dive deeper into hybrid architectures?
Explore how we applied Nemotron's lessons to build specialized SLMs for C++ engineering, or check out our other technical deep dives.