The Magnificent Eight: Why We Built 8 Tiny Models Instead of 1 Big One
You know what's funny? Everyone's racing to build bigger models. 70B parameters, 175B, 405B—the numbers keep climbing. Meanwhile, we're over here training eight 4B-8B models and getting better results for C++ engineering tasks. Not "better for the price" or "better given our constraints"—just better. Let me explain why.

Our eight specialist models: C++, CMake, Debug, Shell, Orchestration, Design, Review, and Algorithm SLMs
The Specialization Thesis: Why Jack of All Trades Fails
Here's the problem with generalist models: they're trained on everything. Python, JavaScript, Java, C++, Go, Rust, documentation, conversations, creative writing, code reviews, bug fixes—all mixed together in a trillion-token soup. The model learns patterns, sure, but it learns them averaged across all domains.
When you ask GPT-4 to debug a C++ template metaprogramming error, it's pulling from the same weight matrices that handle Python list comprehensions and JavaScript async/await. The knowledge is there, buried somewhere, but it's competing with every other language pattern it's ever seen. You're getting the average response across all programming contexts, not the expert response for C++.
What Happens When Models Specialize
Instead of one 70B model that knows a little about everything, we have:
- C++ SLM (7B params): Trained exclusively on 150B tokens of C++ code, discussions, compiler errors, and fixes. It knows the C++ standard library like the back of its hand. Template errors? SFINAE failures? Undefined behavior? This model has seen thousands of examples.
- CMake SLM (4B params): 100B tokens of CMakeLists.txt files, build configurations, platform-specific quirks. It knows why your cross-compilation is failing before you finish typing the error message.
- Debug SLM (6B params): Core dumps, GDB sessions, Valgrind output, AddressSanitizer logs. Trained on 120B tokens of actual debugging sessions from real codebases.
Each model is small enough to fit in 48GB GPU memory, fast enough to run on consumer hardware, and specialized enough to outperform GPT-4 in its domain.
The magic is in the focus. A 7B model trained on 150B tokens of only C++ sees way more C++ patterns than a 70B model trained on 1T tokens of everything. It's not about total parameter count—it's about parameters per domain.
Bigger Isn't Always Better: The Math
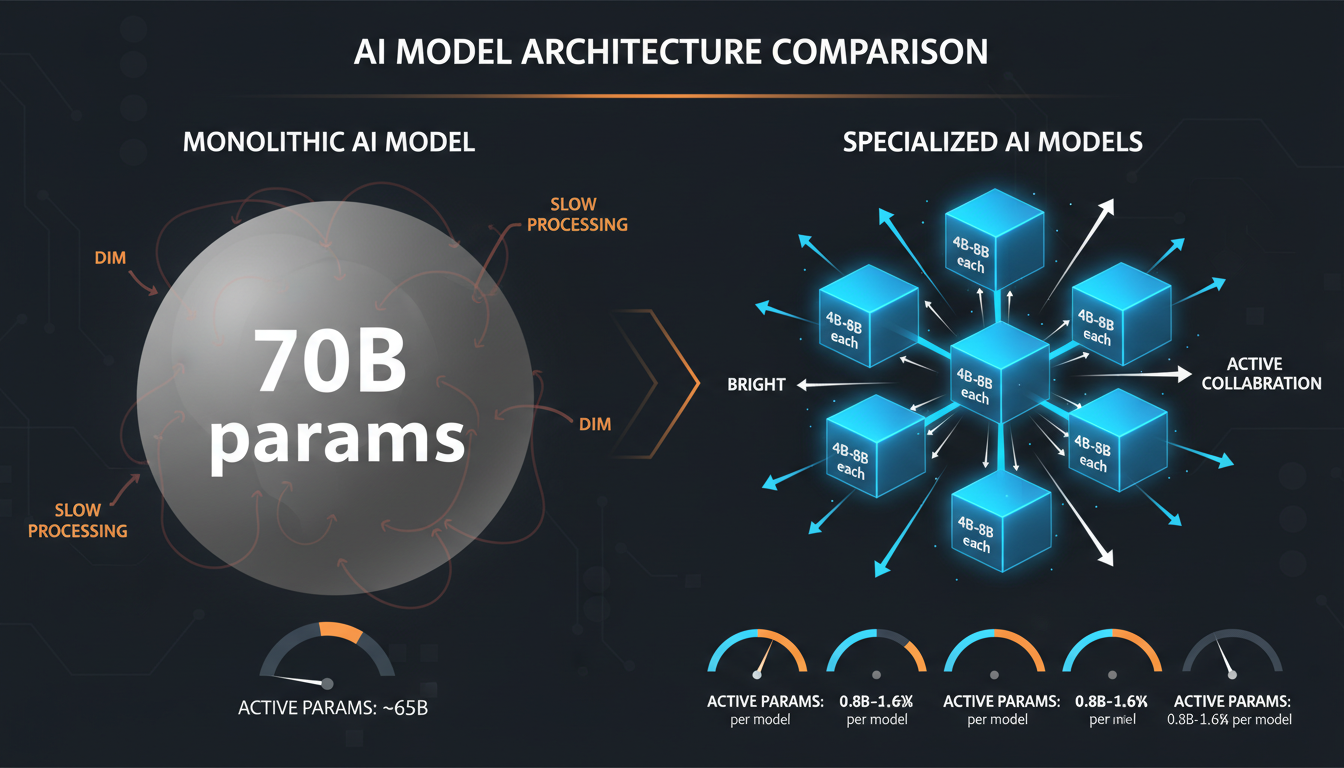
70B parameters spread across all knowledge vs. 40B total parameters focused on specific domains
Let's do the math. A 70B parameter model trained on 1 trillion tokens has seen roughly 14 tokens per parameter. Sounds good, right? Except those tokens are spread across every possible domain. For C++ specifically, maybe 5% of the training data—so 50B C++ tokens for 70B parameters. That's 0.7 C++ tokens per parameter.
Our C++ SLM: 7B parameters, 150B C++ tokens. That's 21 tokens per parameter—all C++, no dilution. The model doesn't need to "remember" how Python works or what JavaScript promises do. Every parameter is optimized for one thing: understanding C++.
Effective Specialization: The Numbers
50B tokens ÷ 70B params = 0.7
150B tokens ÷ 7B params = 21.4
Result: Our specialist sees 30x more C++ per parameter than the generalist. That's why it's better—not despite being smaller, but because it's smaller and focused.
MoE Magic: 4B-8B Models with 0.8B-1.6B Active
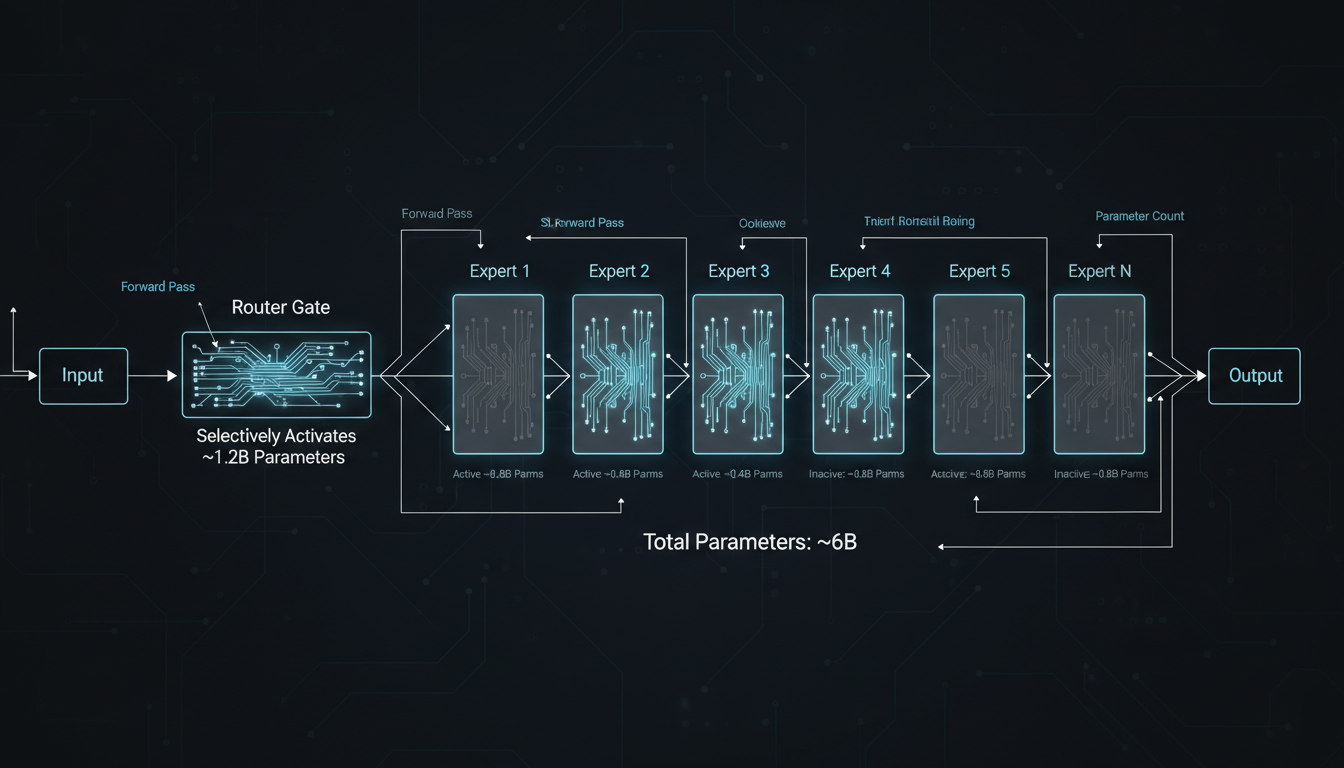
MoE routing: only 0.8B-1.6B parameters active per forward pass, selected by learned routers
Here's where it gets interesting. Each of our models isn't just a dense 4B-8B parameter blob. They're Mixture of Experts (MoE) architectures, which means most of the parameters are sitting idle at any given time.
When you feed a C++ template error into the C++ SLM, a router layer looks at the input and says, "Okay, this is about template instantiation depth limits—activate Expert 3 and Expert 7, keep the rest off." Only 0.8B-1.6B parameters light up. The rest? Silent. This has two huge benefits:
Why MoE Works for Specialists
Inference is 3-5x faster than a dense 7B model because you're only running 1.6B parameters per token. On a single GB10, we hit 200+ tok/s. Try that with a 70B model.
Even within "C++," there are subdomains: templates, concurrency, memory management, standard library. Each expert can focus on one of these. The router learns which expert handles what. It's specialists all the way down.
The catch: training MoE is harder. You need to balance expert utilization (avoid "dead" experts) and prevent mode collapse (all queries going to one expert). We use load-balancing losses and auxiliary objectives. It's fiddly, but it works.
The 4B-8B total parameter count is the capacity—it's what you load into memory. The 0.8B-1.6B active count is the cost per query—it's what you actually compute. This asymmetry is why MoE models feel like they punch way above their weight. You get the knowledge of a big model with the latency of a small one.
Why Not One Big MoE Model?

The generalist: doing everything, mastering nothing
Good question! Why not train one massive MoE with 50B total parameters, 128 experts, and let the router sort it out? We tried. It didn't work. Here's why:
With 128 experts covering all possible domains, the router never learns clean boundaries. Is Expert 42 for C++ templates or Python decorators? Both? The model ends up hedging, activating multiple experts that partially overlap, wasting capacity.
C++ might be 5% of your training set, Python 20%, JavaScript 15%. The Python experts get way more gradient updates. By the end of training, the C++ experts are undertrained and the Python experts are overtrained. You can try to fix this with sampling tricks, but it's a losing battle.
A single big MoE still shares the embedding layer, attention heads, and final projection across all domains. Those layers learn averaged representations. You don't get the pure specialization you want—you get a "pretty good at everything" model, which is exactly what we're trying to avoid.
By splitting into eight separate models, we can train each one on a curated dataset for its domain. The C++ SLM never sees Python code. The CMake SLM never sees JavaScript. Every expert, every layer, every parameter optimizes for one thing. That's how you get actual expertise instead of diluted competence.
Meet the Team: Our Eight Specialists
Each model has a job. Here's the lineup:
C++ SLM (7B params)
Training: 150B tokens of C++17/20/23 code, proposals, compiler errors, stack traces.
Specialty: Template metaprogramming, UB detection, standard library usage, modern C++ idioms.
CMake SLM (4B params)
Training: 100B tokens of CMakeLists.txt, build scripts, platform configs.
Specialty: Cross-platform builds, dependency resolution, generator expressions, find_package() magic.
Debug SLM (6B params)
Training: 120B tokens of GDB sessions, core dumps, sanitizer logs, debugging narratives.
Specialty: Root cause analysis, memory corruption, race conditions, valgrind output interpretation.
Shell SLM (4B params)
Training: 80B tokens of bash/zsh scripts, CI/CD configs, deployment automation.
Specialty: Scripting, piping, environment setup, Docker/Kubernetes orchestration.
Orchestration SLM (5B params)
Training: 100B tokens of agent dialogues, task planning, multi-step workflows.
Specialty: Breaking complex tasks into subtasks, coordinating between specialists, error recovery.
Design SLM (6B params)
Training: 110B tokens of design docs, architecture discussions, API proposals.
Specialty: System design, interface planning, trade-off analysis, refactoring strategies.
Review SLM (5B params)
Training: 90B tokens of code reviews, diffs, PR discussions, style guides.
Specialty: Code quality, style violations, bug detection, improvement suggestions.
Algorithm SLM (7B params)
Training: 170B tokens of algorithm textbooks, competitive programming, pseudocode.
Specialty: Pseudocode-to-C++ conversion, complexity analysis, data structure selection, algorithm optimization.
Total: ~44B parameters across 8 models, 920B+ tokens of training data. Each model fits comfortably in 48GB GPU memory (remember, MoE means only 0.8B-1.6B active). You can run the whole ensemble on a single 8-GPU node and get sub-second responses for almost any C++ engineering query.
What We Learned Building This
For domain-specific tasks, a 7B specialist will beat a 70B generalist every time. But you need enough capacity to learn the domain. We tried 1B models—too small. 4B-8B seems to be the sweet spot for technical domains.
Training on "all C++ code on GitHub" doesn't work. You need high-quality examples: well-commented code, discussions explaining why something is done a certain way, error messages paired with fixes. Quality over quantity, always.
Getting the routers to balance expert usage takes careful tuning. Too aggressive load-balancing, and you force bad routing decisions. Too lenient, and some experts never activate. We use entropy regularization on router outputs and auxiliary losses to encourage diversity.
Having 8 specialists is great, but you need something to coordinate them. That's what the Orchestration SLM does—it decides which specialist to call for a given query. This is actually the hardest model to train because it needs to understand all the domains well enough to route correctly.
The Real Takeaway
In the rush to build ever-larger models, we've forgotten that intelligence isn't just about capacity—it's about focus. A 70B generalist knows a little about everything. Our 8 specialists know a lot about one thing each. For real engineering work, depth beats breadth.
MoE architectures make this practical: you get the capacity of a big model (4B-8B total params) with the speed of a small one (0.8B-1.6B active). Each specialist can run on consumer hardware, respond in real-time, and outperform models 10x larger in its domain.
We're not saying specialist models are always better. If you need a chatbot that can discuss recipes and write poetry and explain quantum mechanics, yeah, use GPT-4. But if you need an AI that actually understands why your C++ template instantiation is failing? Give me a focused 7B specialist over a distracted 70B generalist any day.
Sometimes smaller is better. You just have to be brave enough to specialize.
Want to learn more about our SLM Ensemble?
Check out our other technical deep dives on training infrastructure, hybrid architectures, and what it takes to build AI that actually understands C++.