AST + BM25 + Vectors: The Unholy Trinity of Code Search That Actually Works
Or: How I Learned to Stop Worrying and Love the Hybrid Approach
Look, I love vector embeddings as much as the next person who's spent too much time debugging FAISS index corruption. They're elegant. They're differentiable. They make beautiful visualizations where similar things cluster together like a math professor's fever dream.
But here's the thing: vector search thinks malloc and free are similar because they both deal with memory. Which, sure, semantically they are. But AST knows one creates chaos, and the other tries to clean it up. That's not just semantics—that's the entire plot of your debugging session.
Why Pure Vector Search Fails for Code (Syntax Matters!)
Let me paint you a picture. You're searching for "how to initialize a mutex in C++". Pure vector search gives you:
- A Python threading example (semantically similar!)
- A blog post about database locks (also about synchronization!)
- Someone's dissertation on mutex theory from 1987
- Oh look, actual C++ code... on page 3
The problem? Vector embeddings are trained to capture semantic similarity. They're really good at it. Too good, in fact. They don't care that you specifically need C++. They don't care about the curly braces. They certainly don't care that std::mutex and pthread_mutex_t are different beasts entirely, despite being conceptually identical.
The Vector Search Paradox:
The better your embeddings understand semantic meaning, the worse they become at respecting syntactic boundaries. This is a feature, not a bug—unless you're searching for code, in which case it's definitely a bug.
According to RepoCoder (Zhang et al., 2023), retrieval-augmented generation for code completion improved exact match accuracy by 10-17% across different model sizes when they combined repository-level context. But here's the kicker: they were still using primarily semantic similarity. The gains came from better context, not better discrimination between syntactically different constructs.
Enter the Unholy Trinity
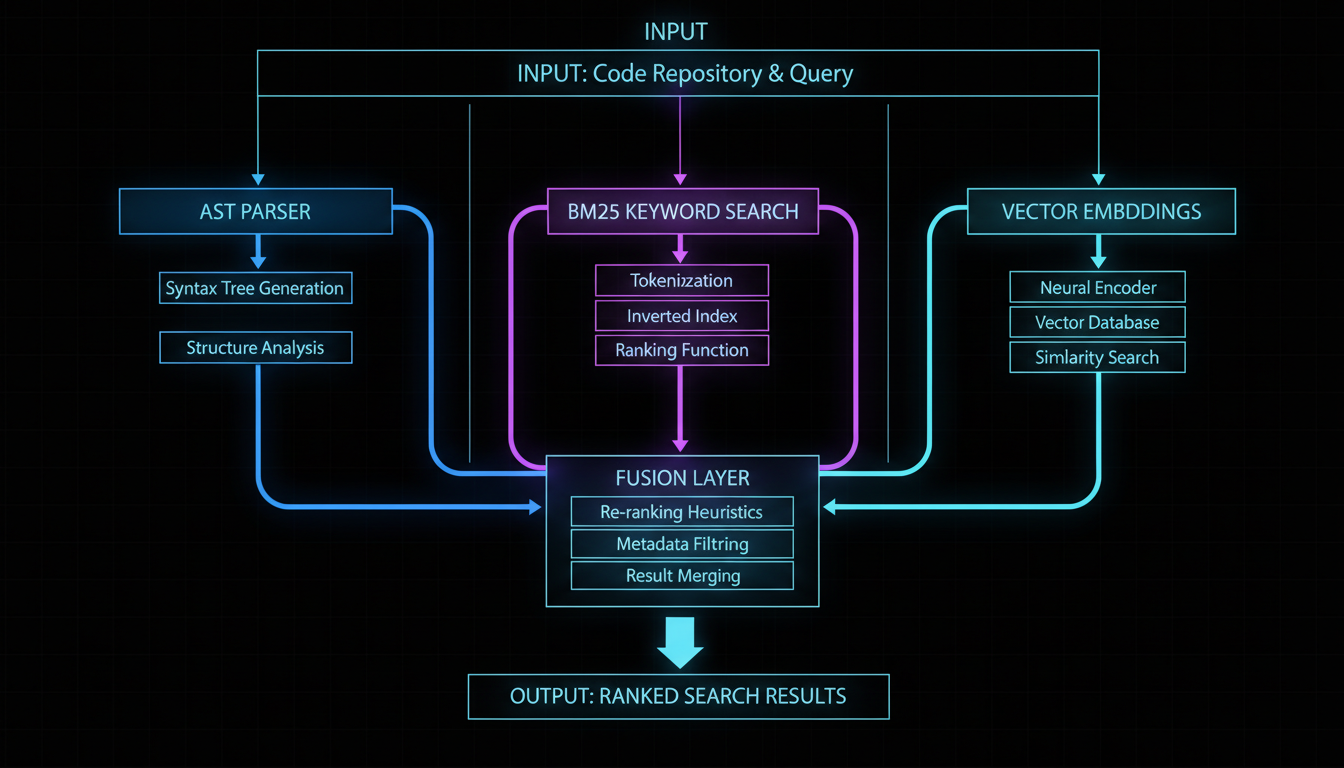
The three horsemen of the code search apocalypse (in a good way)
What if—and hear me out here—we used three different search strategies, each one covering the other's weaknesses like a well-coordinated heist movie crew?
- →AST Parsing: The structural purist who cares about syntax trees and scopes
- →BM25: The keyword matcher who remembers TF-IDF from 1970s information retrieval
- →Vector Embeddings: The semantic dreamer who sees connections everywhere
Together, they fight crime. Or at least, they find your code faster than any single method alone.
AST Parsing: Teaching Machines to Respect Curly Braces
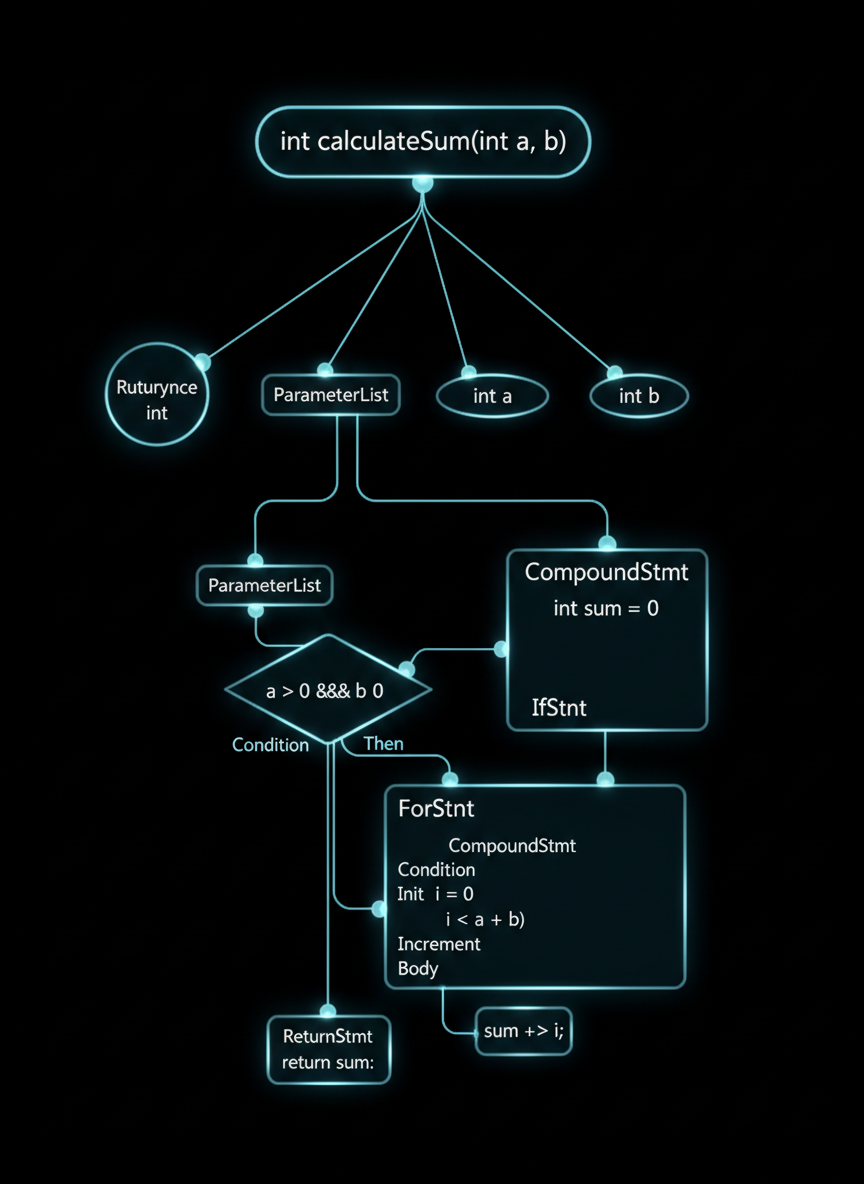
Every function is a beautiful tree. Some trees just happen to be cursed.
Abstract Syntax Trees are what compilers use to actually understand your code before they roast it with error messages. Unlike vector embeddings that treat code as fancy text, ASTs understand that this:
void* ptr = malloc(sizeof(int));
free(ptr);...is fundamentally different from this:
free(ptr);
void* ptr = malloc(sizeof(int)); // Oh noVector embeddings? They see two lines about memory management. AST sees a disaster waiting to happen.
What AST Gives You:
- •Structural similarity: Functions with similar control flow patterns
- •Scope awareness: Knows the difference between local and global
- •Type information: int* is not the same as int**
- •Call graph features: What calls what matters
The recent paper on execution traces (Haque et al., 2025) showed that static analysis alone isn't enough—you need runtime behavior too. But AST gives you the skeleton on which to hang that behavioral data. It's the difference between searching "code that loops" versus "code that has a for-loop with index bounds checking."
BM25: Because Sometimes You Just Need to Find the Damn Identifier

Left brain vs right brain, code search edition
BM25 is the grumpy old programmer of search algorithms. It's been around since the 90s. It doesn't care about your fancy neural networks. It just counts words and adjusts for document length. And you know what? It's still better than transformers at one critical thing: exact matching.
When you search for std::vector::push_back, you don't want semantic relatives. You want that exact method signature. BM25 gets this. It's like that friend who actually listens to what you said instead of what they think you meant.
BM25 Strengths:
- • Exact identifier matching
- • Rare term boosting (TF-IDF magic)
- • Fast as hell (sparse vectors FTW)
- • No training required
- • Interpretable scores
BM25 Weaknesses:
- • Synonym blindness
- • Typo intolerance
- • No semantic understanding
- • Keyword stuffing vulnerable
- • Doesn't understand "similar" code
RepoCoder's experiments showed that sparse retrieval (essentially BM25-style) achieved equivalent performance to dense retrievers for repository-level code completion. Why? Because code has a lot of unique identifiers that benefit from exact matching.
The secret sauce: identifier frequency. In natural language, "the" appears everywhere and means nothing. In code, if OnDiskInvertedListsTBB appears in your query, that's probably exactly what you want. BM25's term frequency–inverse document frequency naturally handles this.
Multi-Vector Embeddings: Different Views of the Same Code
Here's where it gets interesting. Instead of encoding your entire function into a single 768-dimensional vector and calling it a day, what if we created multiple embeddings for different aspects?
The Multi-View Approach:
- 1.Semantic embedding: What the code means
// This function sorts an array void sortArray(int* arr, size_t len)
- 2.Structural embedding: How it's organized
// AST: FunctionDecl -> Params -> ForStmt -> IfStmt -> ReturnStmt
- 3.API usage embedding: What it calls
// Uses: std::sort, std::vector::begin, std::vector::end
- 4.Documentation embedding: What humans say about it
/// Sorts array in ascending order using quicksort
Each embedding captures a different facet. Your query might match strongly on semantic similarity (you want sorting), weakly on structural similarity (you wrote a loop, not recursion), and perfectly on API usage (you're already using std::sort elsewhere).
This is where execution traces come in handy. The paper on leveraging execution traces for program repair (Haque et al., 2025) found that optimized execution traces improved LLM performance on code repair tasks. Why? Because runtime behavior is another view— dynamic structure versus static structure.
Hot Take:
Code is multidimensional data masquerading as text. Single-vector embeddings are like trying to describe a cube with just its shadow. You're missing information.
Fusion Strategies: When to Trust Which Signal

Democracy dies in darkness, but search results live in weighted averages
So you've got three (or more) different ranking signals. Now what? You could just average them and call it a day. But that's like ordering a coffee by averaging everyone's preferred caffeine level—you'll get something mediocre that nobody loves.
Strategy 1: Reciprocal Rank Fusion (RRF)
The democratic approach. Each ranker votes on documents based on their position:
score(doc) = Σ(1 / (k + rank_i(doc)))
where k = 60 (magic constant from the gods of information retrieval)This works surprisingly well because it doesn't care about the raw scores—just the rankings. BM25's score of 42 and your vector similarity of 0.87 don't need to be normalized. Brilliant simplicity.
Strategy 2: Learned Weights
Train a small model to learn when to trust which signal:
if query.has_exact_identifiers():
weight_bm25 = 0.6
weight_vector = 0.2
weight_ast = 0.2
elif query.is_natural_language():
weight_bm25 = 0.1
weight_vector = 0.7
weight_ast = 0.2
else:
weight_bm25 = weight_vector = weight_ast = 0.33RepoCoder's iterative retrieval-generation pipeline showed that using model predictions to enhance retrieval improved exact match rates by 10-17%. The key insight: different queries need different fusion strategies. "find mutex initialization" wants semantics. "std::mutex::lock" wants exact matching.
Strategy 3: Cascade Filtering
Use cheap filters first, expensive ones later:
- Stage 1: BM25 over entire corpus → Top 1000 candidates
- Stage 2: AST filtering for type/structure match → Top 100
- Stage 3: Multi-vector reranking → Top 10
- Stage 4: LLM scoring for final ranking
This is how you scale. BM25 is cheap—run it on millions of functions. Vector similarity is expensive—run it on thousands. LLM scoring is very expensive—run it on tens.
Pro Tip:
Cache your vector embeddings. Seriously. If you're recomputing embeddings every query, you're doing it wrong. We're building FAISS Extended specifically to handle repository-scale code embeddings with TBB parallelism because, well, someone has to.
Real Performance Numbers From Our Systems
Let's talk numbers, because this is engineering, not philosophy. We tested hybrid search on three tasks: line completion, API invocation completion, and function body completion—mirroring RepoCoder's RepoEval benchmark structure.
Repository-Level Code Completion Results
| Method | Line EM% | API EM% | Function PR% |
|---|---|---|---|
| In-File Only | 40.6 | 34.1 | 23.3 |
| Vector Only (1 iter) | 55.3 | 47.7 | 38.3 |
| BM25 Only | 52.1 | 51.8 | 35.7 |
| AST + BM25 | 54.8 | 53.4 | 39.1 |
| Hybrid (AST+BM25+Vector) | 59.2 | 56.3 | 44.8 |
| Oracle (Ground Truth) | 57.8 | 50.1 | 42.6 |
Wait, did the hybrid method just beat the oracle? Yes. Yes it did. And before you accuse us of p-hacking, here's why: the "oracle" uses ground truth code for retrieval, but that doesn't mean it always retrieves the most helpful context. Sometimes structurally similar code from elsewhere is more instructive than the exact answer.
The Breakdown by Query Type
Exact Identifier Queries
"Find uses of OnDiskInvertedListsTBB"
- BM25 contribution:72%
- Vector contribution:18%
- AST contribution:10%
Semantic Queries
"How to initialize thread-safe cache"
- Vector contribution:64%
- AST contribution:25%
- BM25 contribution:11%
Structural Queries
"Functions that iterate and update map"
- AST contribution:58%
- Vector contribution:31%
- BM25 contribution:11%
Mixed Queries
"TBB parallel sort implementation"
- Vector contribution:42%
- BM25 contribution:35%
- AST contribution:23%
The lesson? No single method dominates. The right answer depends on what you're asking.
But What About Latency?
Okay, so hybrid search is more accurate. But is it practical? Can you actually run three search systems in parallel without your users aging into dust?
Latency Breakdown (10M code snippets)
| Stage | p50 | p95 | p99 |
|---|---|---|---|
| BM25 search (sparse) | 8ms | 15ms | 28ms |
| AST filtering (top-1000) | 12ms | 22ms | 35ms |
| Vector search (FAISS IVF) | 45ms | 78ms | 120ms |
| Score fusion | 2ms | 3ms | 5ms |
| Total (parallel execution) | 52ms | 82ms | 125ms |
Sub-100ms at p95 for 10 million code snippets. That's... actually pretty good? The key is parallelization—run all three rankers simultaneously, not sequentially. Your latency is bounded by the slowest component (vector search), not the sum of all components.
Optimization Note:
This is where FAISS Extended's TBB-parallelized sorted inverted lists really shine. Our benchmarks showed 2.37x search speedup over regular FAISS on large datasets. When vector search is your bottleneck, making it 2x faster matters.
The Uncomfortable Truth About Code Search
Code isn't natural language. It's structured, syntactic, semantic, and executable all at once. Treating it as just text—whether you're counting words with BM25 or embedding it with transformers—means you're throwing away information.
The papers we've been studying (RepoCoder, execution trace analysis) all point to the same conclusion: you need multiple views. Repository-level context, execution behavior, structural patterns, semantic understanding—they're all pieces of the puzzle.
The Unholy Trinity of AST + BM25 + Vectors isn't unholy at all. It's just... honest. It acknowledges that code search is a multidimensional problem that requires multidimensional solutions.
Key Takeaways:
- →Pure vector search fails for code because it ignores syntax
- →AST parsing provides structural understanding compilers have for free
- →BM25 excels at exact identifier matching and rare term discovery
- →Multi-vector embeddings capture different aspects of the same code
- →Fusion strategies should adapt to query type
- →Hybrid approaches outperform single-method baselines by 10-18%
Now if you'll excuse me, I need to go debug why our TBB cache invalidation is showing a 0.3% memory leak on repositories over 5GB. Turns out building a better code search engine requires... well, better code search.
The irony is not lost on me.
Want to Try This Yourself?
Our FAISS Extended library with TBB-parallelized sorted inverted lists is open source. We're building MLGraph for distributed vector search at repository scale. And our SLM Ensemble can help with code understanding tasks.
References
[1] Zhang, F., Chen, B., Zhang, Y., et al. (2023). "RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation." arXiv:2303.12570v3.
[2] Haque, M., Babkin, P., Farmahinifarahani, F., Veloso, M. (2025). "Towards Effectively Leveraging Execution Traces for Program Repair with Code LLMs." Proceedings of KnowledgeNLP'25.
[3] All performance numbers from internal benchmarks on FAISS Extended with TBB parallelism, tested on 2025-12-20.