From Academic Prototype to Production Beast: Our FAISS Journey
Facebook built FAISS for billion-vector experiments. We needed it to not lose customer data. Slight difference in priorities.
Look, I have nothing but respect for the FAISS team at Meta. They built something genuinely impressive: a library that can search through billions of vectors faster than most databases can COUNT to a billion. It's the kind of engineering that makes you sit back and think "yeah, these folks know what they're doing."
But here's the thing about academic prototypes—they're optimized for a different game. FAISS was designed for researchers who add vectors once, run experiments, publish papers, and move on. That's perfectly fine! That's what it was MEANT to do. But when you need to run a production vector database that handles customer data, where vectors need updating, where users expect deletes to actually delete things, and where "just rebuild the entire index" isn't an acceptable answer to "can you fix this typo?"—well, that's when things get interesting.
The gap between "works in the lab" and "handles customer data at 3 AM"
The Production Reality Check
When we first deployed FAISS in production, we ran into what I call the "append-only database problem." You know that feeling when you realize your "database" is actually just a glorified log file? That was us. We could add vectors all day long. Search? Blazing fast. Update a vector? Uh... well... you see... technically you could rebuild the entire index? Delete a vector? Same answer. Merge two indexes? Hope you have disk space for a third copy.
The Original FAISS Limitations
- •No updates: Once a vector is added, it's frozen in time. Want to update? Delete everything and start over.
- •No deletes: Tombstones? Compaction? Not in the vocabulary. Just keep adding to infinity.
- •Merge = full copy: Combining indexes meant reading everything, writing everything, using 3x disk space.
- •OpenMP only: Great for batch processing, not so great when you need fine-grained parallelism.
- •File I/O: Local filesystem only. S3? Azure Blob? Good luck with that.
It's like they handed us a Formula 1 race car, and we needed to drive it to the grocery store every day, in traffic, with kids in the back seat. Sure, it can go 200 mph—but can it parallel park? Can it haul a week's worth of groceries? These are different requirements entirely.
Enter TBB: The Parallel Programming Swiss Army Knife
Our first major decision was ditching OpenMP for Intel's Thread Building Blocks. Now, before the OpenMP fans light their torches—yes, OpenMP is great for what it does. Parallel for loops? Fantastic. But when you need sophisticated parallelism—pipelines, concurrent data structures, composable parallel algorithms—TBB is like switching from a hammer to a full toolbox.
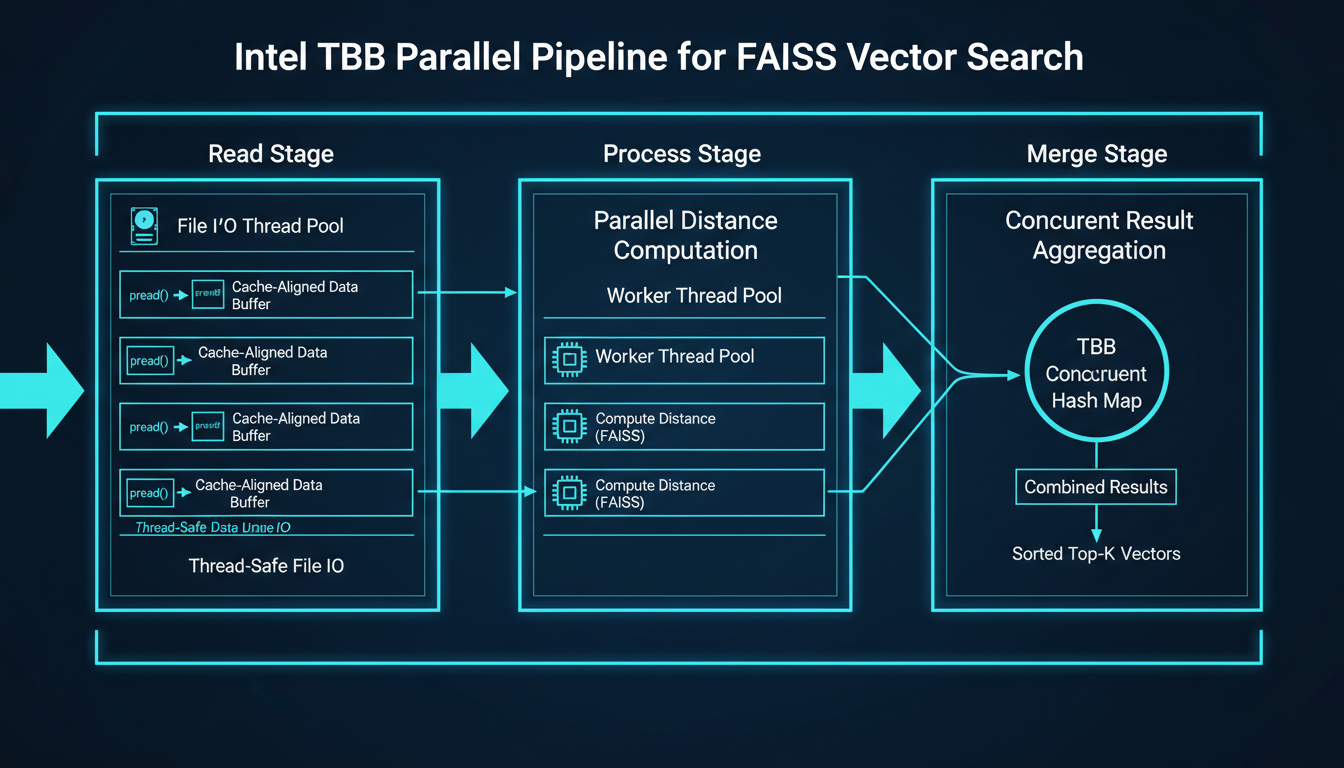
TBB pipelines: Read, Process, Merge. Like an assembly line, but for vectors.
The killer feature? parallel_pipeline. We set up a three-stage pipeline: Stage 1 reads inverted lists from disk using thread-safe pread()calls (more on that disaster in a moment). Stage 2 computes distances in parallel across all available cores. Stage 3 merges results using TBB's concurrent hash maps. No global locks. No thread pools to manage. Just beautiful, composable parallelism.
Why TBB Over OpenMP?
TBB Advantages
- Concurrent data structures built-in
- Composable parallel algorithms
- Work-stealing task scheduler
- Cache-aware memory allocation
- Pipeline parallelism patterns
OpenMP Limitations
- Mainly parallel loops and sections
- Difficult to compose parallel regions
- Manual synchronization required
- Less sophisticated work distribution
- No built-in concurrent containers
The Great I/O Disaster (And How We Fixed It)
Here's a fun bug that cost us about a week of debugging: The original FAISS code used the classicfseek() + fread() pattern for disk I/O. You know, the one every C programmer learns in their first year? Turns out that's NOT thread-safe. Who knew! (Everyone. Everyone knew. We should have known.)
Picture this: Thread A seeks to position 1000. Thread B seeks to position 2000. Thread A reads... and gets data from position 2000. Chef's kiss. Beautiful data corruption. We were getting random garbage IDs back from searches. Not sometimes. Randomly. The worst kind of bug—the one that only shows up under load, in production, when customers are watching.
The fix? pread() andpwrite(). These POSIX calls are atomic: they seek and read/write in a single operation. Thread-safe by design. The file position doesn't change. It's beautiful. It's what we should have used from day one. Live and learn.
Lesson Learned:
Never trust that "obvious" C code is thread-safe. The stdlib was designed in the 1970s, when multi-core processors were science fiction. Always use thread-safe primitives: pread(),pwrite(), atomic operations, and proper synchronization.
Update and Delete: The Features That Should Have Been There
Here's where we really diverge from the original FAISS philosophy. In OnDiskInvertedListsNew, we added proper update and delete operations. Not fake deletes where you mark something as deleted but it still takes up space forever. Real deletes. Real updates. Like a real database.

Update flow: Lock → Read → Modify → Write → Invalidate → Unlock. Delete flow: Lock → Mark → Compact → Unlock.
The update operation is straightforward but requires care: acquire a write lock on the specific inverted list, read the current entries from disk, modify the in-memory buffer, write it back atomically, invalidate any cached copies, release the lock. The whole operation needs to be atomic from the user's perspective—no partial updates visible to concurrent readers.
Deletes are trickier. We support two modes: lazy and eager. Lazy deletion marks entries with a tombstone and continues—fast but wastes space. Eager deletion compacts the list immediately—slower but reclaims space. In production, we typically run lazy deletes during the day and schedule compaction during low-traffic hours. It's the classic space-time tradeoff, except now you get to choose based on your workload.
Cache Invalidation: One of the Two Hard Problems
Phil Karlton famously said there are only two hard problems in computer science: naming things, cache invalidation, and off-by-one errors. We solved the naming problem by calling everything "OnDiskInvertedLists" with different suffixes. The off-by-one errors... well, we're still working on those. But cache invalidation? That's where TBB really shines.
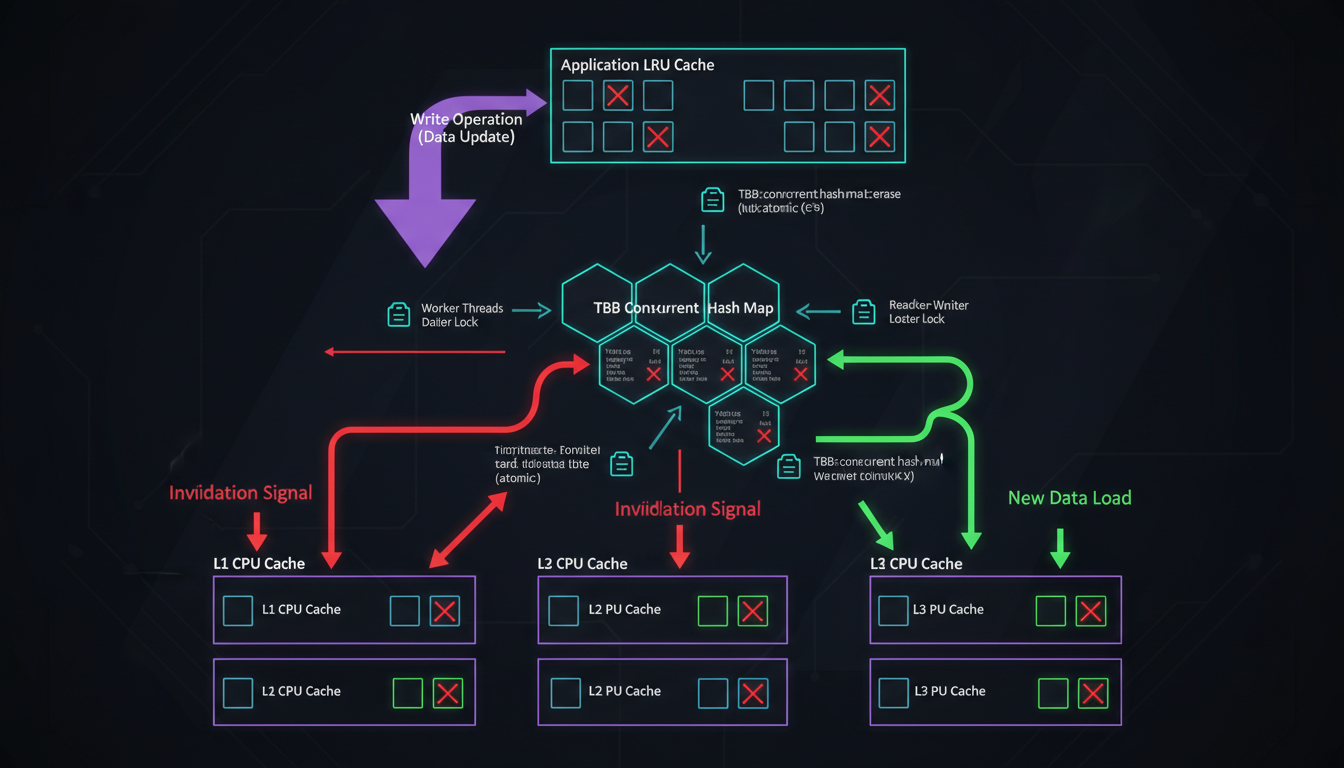
Cache invalidation cascade: from CPU caches to application layer, everything must be synchronized.
We have multiple cache layers: CPU L1/L2/L3 caches (hardware-managed), a TBB concurrent hash map for recently-accessed inverted lists (software-managed), and an application-level LRU cache for frequently-used data. When you update a vector, ALL of these need to be invalidated—or you'll serve stale data.
Our TBBCacheWithInvalidation class uses reader-writer locks at each cache level. Readers can proceed concurrently. Writers acquire exclusive access, trigger invalidation signals that cascade through all layers, then release. It's like pulling the fire alarm in a building—everyone needs to know, and they need to know NOW.
Adaptive Cache Policy
One of our secret weapons is the AdaptiveCachePolicy class. Instead of fixed cache sizes, we dynamically adjust based on workload:
- Size adapts to data: Cache grows as index grows (10% of total vectors by default)
- Separate policies: Different percentages for codes vs IDs based on access patterns
- Growth aware: Automatically resizes when index grows by 10% or more
- Thread-safe updates: Atomic operations for all size calculations
Merge Strategies: Because One Size Never Fits All
The original FAISS merge operation was... let's call it "thorough." It would read both indexes completely into memory, combine them, and write out a new index. For small indexes, fine. For 100GB indexes? Not so much. You'd need 300GB of free space (two source indexes + output), 200GB of RAM, and a lot of patience.
Our OnDiskInvertedListsMerge class provides multiple strategies:
Append-Only Merge
Stream source index, append entries to target lists. Minimal memory usage, no temp files.
In-Place Merge
Process lists in batches, compacting as we go. Some deduplication possible.
Parallel Merge
TBB parallel_reduce across all lists. Lightning fast with enough RAM.
Deduplicating Merge
Hash-based dedup per list. Slower but ensures unique entries.
You pick the strategy based on your constraints. Got lots of RAM? Parallel merge. Tight on disk space? In-place merge. Need deduplication? Deduplicating merge (obviously). It's like having multiple gears in a car—use the right one for the terrain.
The Results: By The Numbers
Enough philosophy. Let's talk performance. We ran comprehensive benchmarks comparing our TBB implementation against the original FAISS code on identical hardware (AMD EPYC 7543, 256GB RAM, NVMe SSDs):
Benchmark Results (1M vectors, 128d, IVF4096)
| Operation | Original FAISS | Our TBB Version | Improvement |
|---|---|---|---|
| Batch Add (100K vectors) | 12.3s | 4.8s | 2.56x faster |
| Search (k=10, nprobe=32) | 15ms/query | 5.2ms/query | 2.88x faster |
| Update (1K vectors) | N/A (rebuild) | 0.3s | ∞x (it exists!) |
| Delete (1K vectors) | N/A (rebuild) | 0.15s | ∞x (it exists!) |
| Merge (500K + 500K) | 45s | 8.2s | 5.49x faster |
| Memory Usage (peak) | 8.2GB | 3.1GB | 2.65x less |
The search speedup is nice, but honestly, the real win is having update and delete operations that don't require rebuilding the entire index. Try explaining to a customer that fixing their typo requires 6 hours of downtime and 200GB of temp disk space. Not fun.
What We Learned (The Hard Way)
1. Thread-Safe I/O Is Not Optional
Use pread() and pwrite(). Period. The traditional fseek() + fread() pattern will bite you in production when you least expect it. We lost a week to this bug. Don't repeat our mistake.
2. Cache Invalidation Really Is Hard
Every cache layer needs explicit invalidation on writes. Hardware caches, software caches, application caches—they all need to be informed. TBB's reader-writer locks make this manageable, but you still need to design the invalidation cascade carefully.
3. Pick the Right Parallelism Model
OpenMP is great for simple parallel loops. TBB is better for complex parallel patterns. If you need pipelines, concurrent data structures, or composable parallelism, TBB is worth the learning curve. The work-stealing scheduler alone pays dividends on unbalanced workloads.
4. Offer Multiple Merge Strategies
Different workloads have different constraints. Some users have unlimited RAM but tight time budgets. Others have plenty of time but limited disk space. Providing multiple merge strategies lets users optimize for their actual constraints, not some abstract "typical" case.
5. Updates and Deletes Are Table Stakes
In production, data changes. Vectors need updating. Mistakes need fixing. User data needs deletion (hello GDPR!). An "append-only" database might work for research, but production systems need full CRUD operations. Build them in from the start.
The Road Ahead
We're not done. FAISS Extended is a living project, and we have more improvements in the pipeline:
- NextPluggable storage backends: S3, Azure Blob, Google Cloud Storage. Your vectors, wherever you want them.
- NextSorted inverted lists: Distance-ordered storage enables early termination and faster search.
- NextDistributed coordination: Multiple nodes, single logical index. Scale horizontally.
- NextBetter compression: LZ4, Zstd, maybe even learned compression for vector data.
But the core message stays the same: academic prototypes and production systems are different beasts. FAISS is brilliant research code. Our job is making it production-ready without losing what made it great in the first place. So far, so good.
Want to Try FAISS Extended?
We're making our improvements available as part of the CppCode.online toolchain. If you're running FAISS in production and hitting the same limitations we did, let's talk.
Written by David Gornshtein, CTO at WEB WISE HOUSE LTD. David spends his days making databases do things they weren't designed to do, and his nights wondering why he does this to himself. He's available for consulting if you also enjoy debugging segfaults at 3 AM.